
Es imposible ignorar la revolución que han generado herramientas como ChatGPT, DALL-E, Midjourney o GitHub Copilot; y es que la posibilidad de poder escribir un trozo de texto, y que una IA te devuelva una respuesta o una imagen totalmente coherente, y que por sobre todo, sea extremadamente útil, era algo totalmente impensable hace un tiempo atrás.
Esto es lo que se conoce como IA generativa, un tópico que recientemente tocamos, y que puedes revisar aquí:
Lo que tienen en común estas herramientas, es que muchas de estas utilizan como base un LLM, es decir, un Modelo de Lenguaje de Gran Tamaño (Large Language Model; no confundirse con el grado de maestría en leyes, LLM). Por ejemplo, el LLM que emplea ChatGPT y Dall-E es GPT, el cual ahora va en su cuarta iteración; mientras que Bard de Google fue recientemente actualizado a PaLM 2.
Los LLMs son modelos de machine learning relativamente nuevos, cuyas primeras versiones recién aparecieron en el año 2018, aunque como es usual dentro de esta área, solo era para efectos de investigación y uso interno dentro de las organizaciones que las crearon. Recién ahora se han ido masificando al público general, especialmente con la llegada de las herramientas mencionadas anteriormente.
Veamos de qué tratan:
Qué son los Large Language Models (LLM)
Como mencioné antes, un LLM es otro tipo de modelo de aprendizaje automático. Esto significa que su función más básica es encontrar patrones en datos nuevos, a partir de un entrenamiento previamente realizado. Desglosemos un poco esta oración:
Los LLMs son entrenados con una inmensa cantidad de datos (una razón de por qué son “grandes”), provenientes de diversas fuentes, y con distintos formatos. Por ejemplo, GitHub Copilot — una herramienta que permite generar código a partir de una simple instrucción — fue obviamente entrenado con los miles de millones de líneas de código que se encuentran alojadas en los distintos repositorios que están en la plataforma. Por otro lado, GPT-4 fue entrenada con información proveniente de una buena parte de la internet. Una verdadera locura.
En lo que respecta a lo de “encontrar patrones en datos nuevos”, este tipo de modelos lo que hacen, en simple, es predecir las palabras a utilizar, con base en un contexto entregado.
La ventaja que estos modelos de gran tamaño tienen por sobre cualquier otro que sea capaz de procesar el lenguaje humano, es que al ser entrenados no solo aprenden de las palabras en sí, sino que también el contexto y la semántica que hay detrás de ellas. Esto permite que el modelo, por ejemplo, pueda entender aquellas sutiles diferencias que puedan existir en una misma palabra, y que sea capaz generar texto coherente y gramaticalmente correcto.
Por eso es que estos se han vuelto súper populares para generar y procesar todo tipo de texto. La capacidad que tienen para entender el lenguaje humano es tal, que se han convertido en muy buenos traductores, escritores de código (para no decir programadores), instructores, y un largo etcétera.
Naturalmente, la pregunta que es: ¿y cómo son capaces de entender esas tan complejas relaciones que existen entre palabras? Hagamos un doble clic en la estructura de estos modelos.
Transformers: la arquitectura detrás de los LLMs
Los LLMs son el caso de uso más común de los Transformers, un tipo de red neuronal que se basa exclusivamente en el uso de sistemas que, de cierta manera, buscan replicar los mecanismos de atención que tiene el cerebro humano.
En un paper adecuadamente llamado “Attention is all you need” (Vaswani et al. 2017), científicos de Google Brain proponen una nueva arquitectura de redes neuronales basadas exclusivamente en mecanismos de atención. El propósito es presentar una alternativa más eficiente a los otros métodos de deep learning que en ese entonces se estaban usando para procesar lenguaje natural (tales como las redes neuronales recurrentes, o RNNs).
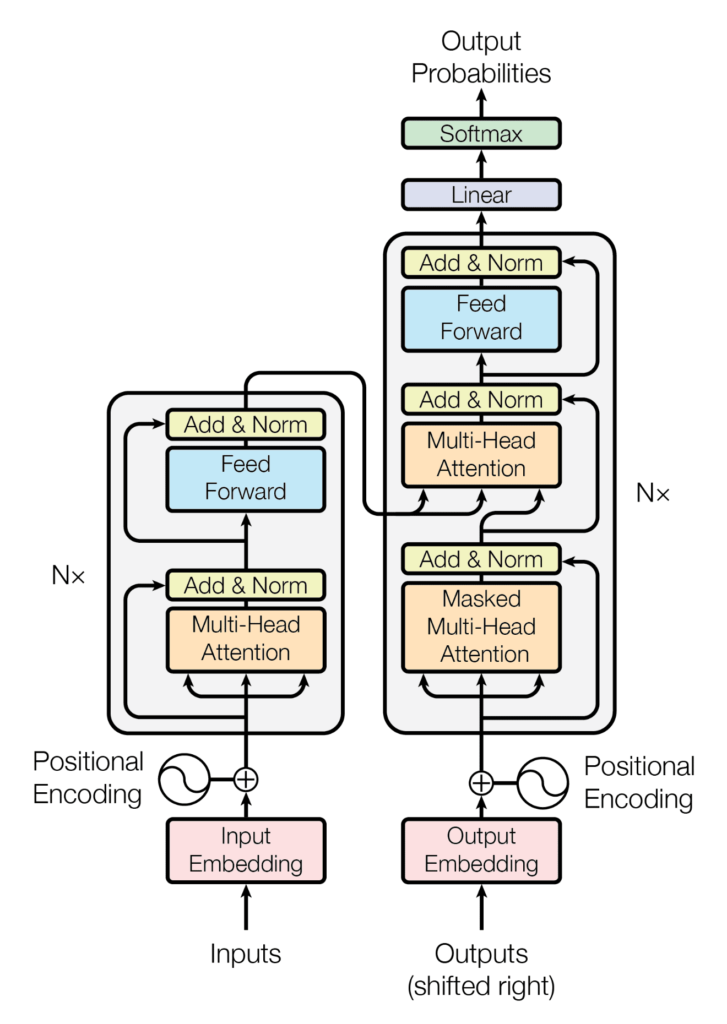
La atención, en el marco de un modelo computacional, puede entenderse como un mecanismo capaz de «enfocarse» en ciertas partes de la entrada (es decir, las líneas de texto) en diferentes momentos durante el proceso de aprendizaje.
En el caso de los Transformers, estos tienen varias capas de atención, las cuales toman la secuencia de palabras, les asigna un peso (un nivel de relevancia) a distintas partes de esta, y luego las mapea en un espacio vectorial. Este proceso se repite en cada una de las capas de un Transformer, refinando así esta representación, para luego dar el resultado final.
Por ejemplo, si tenemos un modelo que está entrenado para traducir del español al francés, lo que hacen estas capas de atención es enfocarse en las partes importantes del texto en español (a través de los pesos calculados). Estos se generan a partir de una “comparación” que se hace entre el trozo en español y su contraparte en francés. A medida que el texto va pasando por las capas, el modelo se enfoca distintas partes de esta, para así generar una salida adecuada en el idioma deseado.
Para efectos prácticos, aquí evidentemente no me estoy adentrando en las complejidades matemáticas de estos modelos — les recomiendo leer el paper si les interesa –, y estoy simplificando bastante el proceso, pero es una buena aproximación a cómo funciona este tipo de red neuronal.
Aplicaciones
Como se podrán haber dado cuenta anteriormente, los Transformers nacieron en Google — algo irónico considerando que actualmente se encuentran un tanto atrás si lo comparamos con Microsoft/OpenAI –, y por lo mismo fueron pioneros en usar esta tecnología. De hecho, BERT (Bidirectional Encoder Representations from Transformers) fue una de las primeras aplicaciones provenientes de esta tecnología, y fue lanzada el año 2018 con fines investigativos.
Actualmente, existen varios LLMs, tales como GPT-4 (OpenAI), LaMDA y PaLM 2 (Google), LLaMa (Meta), entre otros; mientras que sus aplicaciones son variadas, aunque están evidentemente relacionadas con el uso del lenguaje. Y con lenguaje no solo nos referimos al lenguaje humano, sino que también puede ser extendido a otros tipos, tales como los de programación (para generar líneas de código que sean funcionales), e incluso aquellos más complejos, tales como los de la vida.
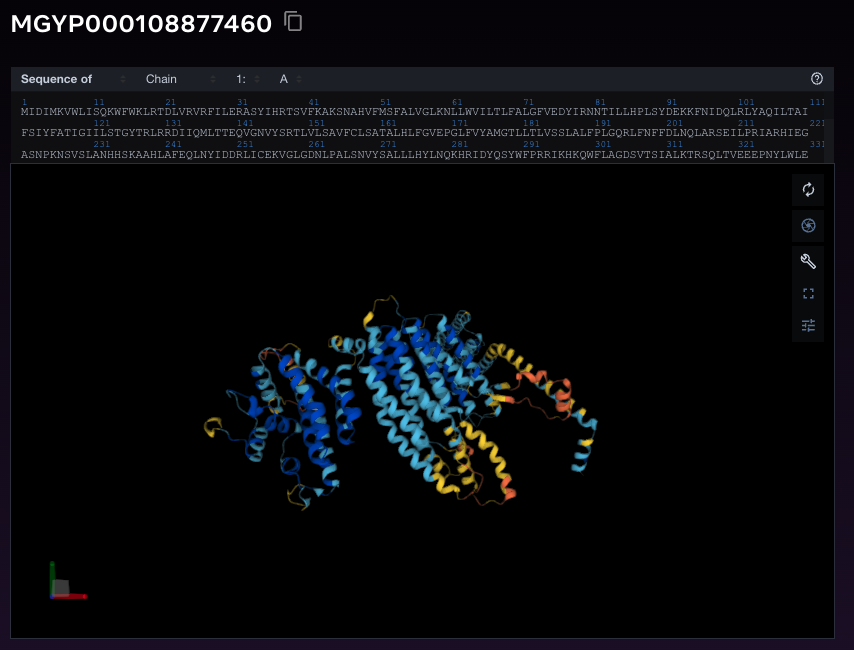
Por ejemplo, Meta utilizó modelos de gran tamaño (ESM-2) para estudiar las estructuras metagenómicas, que son proteínas que se encuentran presentes en distintos organismos de nuestro ambiente, aunque usualmente se concentran en distintos microbios existentes. Su fin es poder mejorar el entendimiento de lo que ellos llaman como la “materia oscura” de las proteínas, a través de la creación de una base de datos que contiene la secuenciación y estructura de distintos prótidos. ¿En dónde entra el LLM aquí? Para predecir la estructura de estas moléculas a partir de la secuencia de nucleótidos que cada una tiene. Según Meta, estos modelos de gran tamaño predicen hasta 60 veces más rápido que los métodos empleados actualmente, manteniendo los mismos niveles de exactitud. Esta base la puedes ver aquí.
NVIDIA tiene un LLM llamado BioNeMo que procesa datos biomoleculares, ya sean químicos, proteicos, o ácidos nucleicos (ADN y ARN), y cuyo propósito es apoyar en el descubrimiento de nuevos medicamentos.
En el área de las finanzas también se está utilizando. Sin ir más lejos, a finales de marzo de este año, Bloomberg presentó su propio modelo de gran tamaño: BloombergGPT, el cual fue entrenado con un enfoque mixto: usando documentos e información financiera que la compañía ya maneja, junto con distintos datasets públicos (probablemente provenientes de internet) con información mucho más general.
Con lo anterior, BloombergGPT es capaz de, por ejemplo, sugerir titulares basados en la información que uno le entrega, hacer consultas sobre diversos tópicos financieros, entre varias otras cosas más.
En el ámbito del consumidor, sus aplicaciones son mucho más sencillas, y principalmente se remiten a tareas como: traducción, generación y sintetización de texto.
Estos se pueden ver en servicios como ChatGPT, Bard, NotionAI, GitHub Copilot, y todos los «Copilot» que Microsoft está implementando en distintos servicios como Teams o Microsoft 365 (ex-Office).
Google también está desplegando para Workspace (su suite de productos enfocados a empresas) un servicio similar, llamado Duet AI, con capacidades para redactar respuestas en Gmail, resumir una cadena de correos electrónicos, generar un documento dadas las instrucciones entregadas por el usuario, etcétera.
En fin, las aplicaciones son varias, y sin dudas estamos solo en el inicio. Poco a poco irán apareciendo nuevos modelos de este estilo que estarán enfocados en tópicos súper específicos, tales como los LLMs desarrollados por Meta o Bloomberg, por lo que la especialización de estos será una de las cosas que más deberemos estar atentos en un futuro.
¿Qué te parecen este tipo de contenidos?
Con información de: Google, Meta, Bloomberg, NVIDIA (1 | 2), Machine Learning Mastery
