
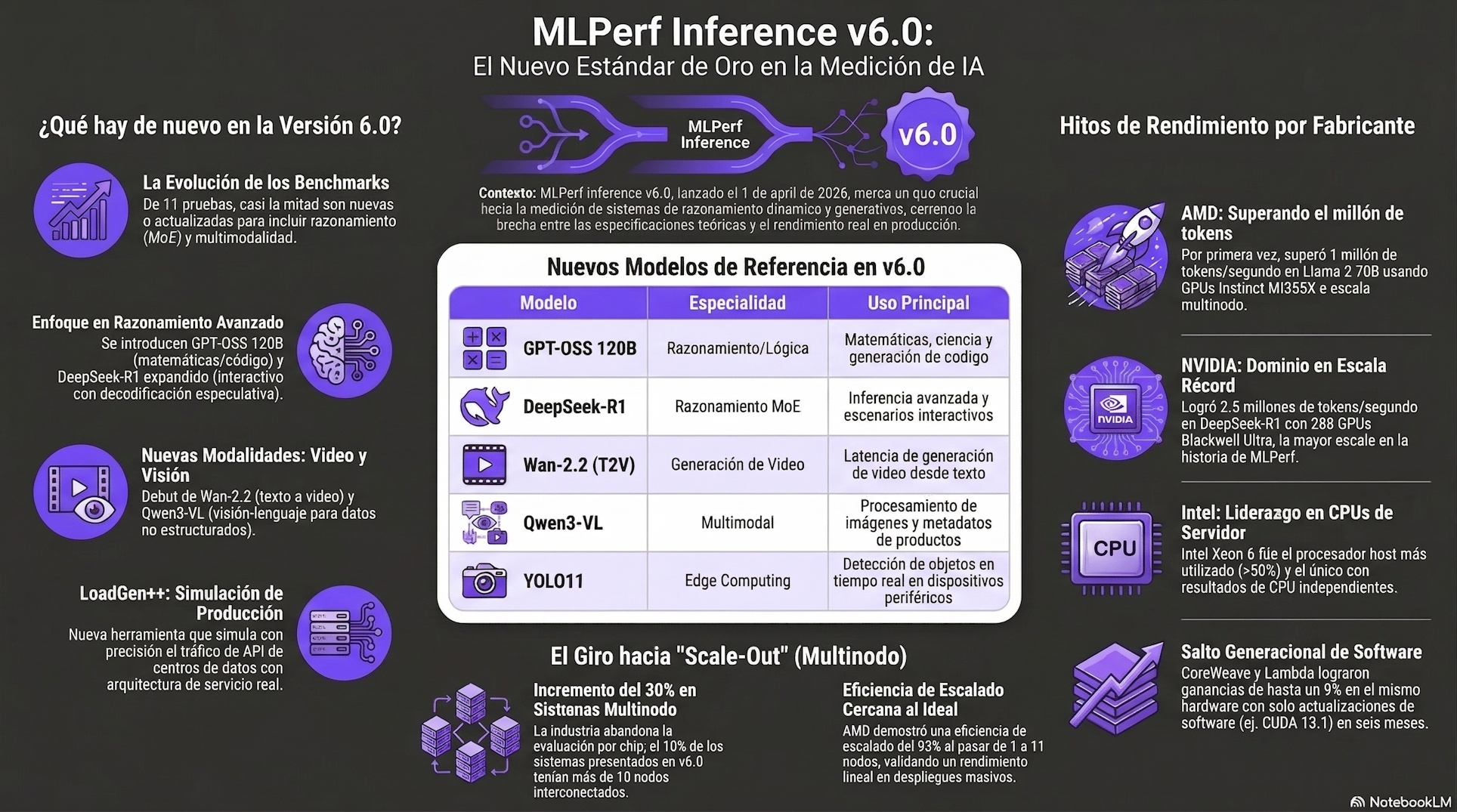
MLPerf Inference v6.0 es una suite de pruebas creada para medir el rendimiento de sistemas de IA en tareas de inferencia. Su valor principal no está en presentar cifras aisladas, sino en ofrecer un marco común para comparar plataformas bajo condiciones equivalentes y con criterios de precisión definidos.
La v6.0 fue publicada el 1 de abril de 2026 por el consorcio MLCommons; y permite comparar sistemas heterogéneos bajo un marco de trabajo que asegura la transparencia y la reproducibilidad de los datos.
¿Qué es exactamente este conjunto de pruebas de MLPerf Inference v6.0 y por qué se compara con una competencia atlética?
MLPerf Inference v6.0 reúne un conjunto de pruebas pensadas para evaluar cómo responden distintos sistemas cuando ejecutan modelos de IA ya entrenados. En este contexto, la inferencia corresponde al momento en que un modelo recibe una entrada y genera una respuesta, ya sea una predicción, una clasificación o una salida generativa.
Dicho de otro modo, MLPerf Inference v6.0 es como un decatlón olímpico donde, en lugar de atletas, tenemos procesadores y software compitiendo en pruebas de velocidad y resistencia. Este estándar asegura que todos los participantes corran en la misma pista y con el mismo calzado, evitando que las empresas inflen sus resultados con trucos de laboratorio.
La utilidad de esta suite está en que fija reglas comunes para la medición. Eso permite comparar hardware y software sin depender de pruebas armadas de forma distinta por cada proveedor, lo que reduce la dispersión de resultados y facilita una lectura técnica más consistente.
Al usar reglas comunes, los compradores de tecnología pueden saber con certeza qué equipo es realmente más rápido procesando un chat o una imagen.
¿Por qué el nuevo examen para grandes modelos de lenguaje separa ahora la velocidad de la precisión?
En esta versión se ha introducido una estrategia para el modelo GPT-OSS 120B donde se separa el examen de velocidad del examen de comprensión. Es como evaluar a un estudiante pidiéndole que escriba rápido en una hoja y, por otro lado, responda preguntas difíciles en otra para confirmar que no está simplemente garabateando.
La medición no se limita a una sola cifra de velocidad. MLPerf también considera variables como el tiempo que tarda un sistema en comenzar a responder y el ritmo con que mantiene la generación posterior, dos elementos relevantes cuando se analizan servicios conversacionales o flujos de inferencia sostenida.
Esta separación busca que los fabricantes no sacrifiquen la calidad de la respuesta solo para ganar una medalla de oro en rapidez. Si el modelo responde tonterías a gran velocidad, el sistema de evaluación lo detecta mediante nuevas pruebas de cumplimiento que anulan el resultado.

¿Cómo se están midiendo los nuevos desafíos de generación de vídeo y detección de objetos?
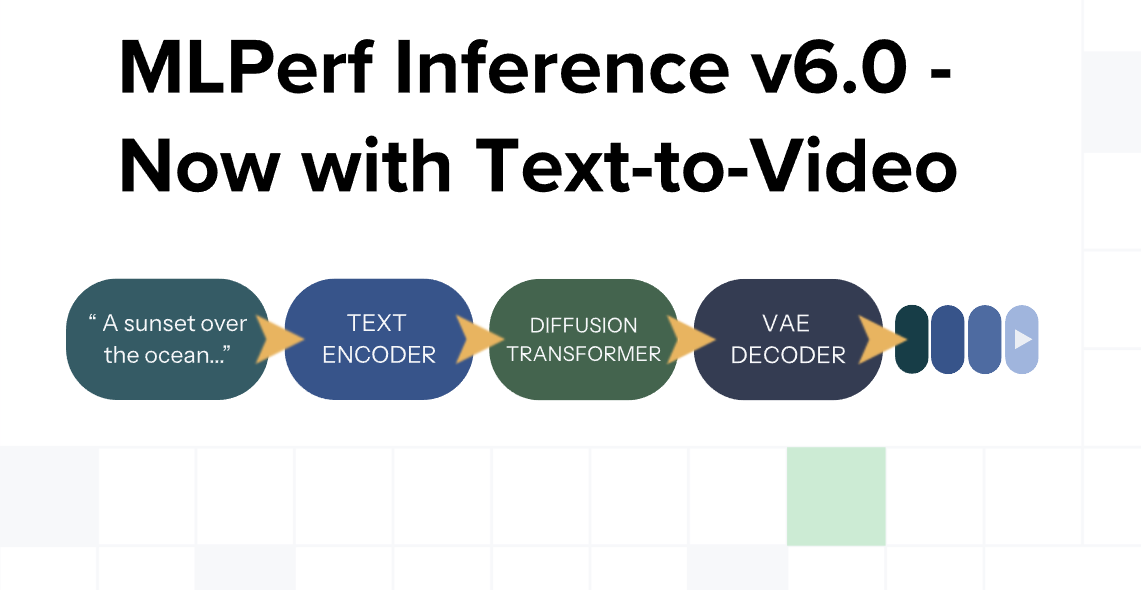
La suite v6.0 incluye por primera vez una prueba de texto a vídeo, lo que equivale a pedirle a un artista que pinte un mural en movimiento en lugar de un cuadro estático. Esta tarea es extremadamente pesada para los servidores y permite ver cuáles son capaces de mantener la fluidez sin que la imagen se rompa o pierda coherencia.
Para los dispositivos más pequeños, como cámaras inteligentes, se ha actualizado el examen al modelo YOLOv11 Large para simular una visión mucho más nítida. Esto obliga a los chips a procesar imágenes en tiempo real con una agudeza visual similar a la de un halcón, descartando el hardware que se queda rezagado en tareas de vigilancia o seguridad.

¿De qué manera las nuevas herramientas como LoadGen++ imitan el tráfico real de internet?
Evaluar un sistema de IA sin tráfico es como probar un auto deportivo en una cinta de correr dentro de un garaje cerrado. La nueva herramienta LoadGen++ funciona como una autopista llena de vehículos, obligando a los servidores a gestionar miles de peticiones simultáneas, tal como ocurre en los servicios que usamos a diario.
Gracias a este entorno de simulación, las empresas pueden verificar si los centros de datos soportan la presión sin colapsar bajo una lluvia de consultas. Los resultados de abril muestran que cada vez se usan infraestructuras más grandes, llegando a conectar cientos de aceleradores para trabajar como un solo cerebro gigante.
Alcance técnico de MLPerf Inference v6.0
Desde una mirada técnica, MLPerf Inference v6.0 funciona como una base metodológica para revisar latencia, rendimiento sostenido y precisión en escenarios definidos. Esa combinación permite observar no solo cuánto procesa un sistema, sino también bajo qué condiciones mantiene resultados aceptables.
Por eso, su interés para la comunidad técnica y científica va más allá de una tabla de marcas. La suite sirve como referencia para estudiar arquitecturas, contrastar implementaciones y entender cómo responden distintas plataformas frente a cargas de trabajo que hoy ocupan un lugar central en la IA.
