
Los anuncios durante el Google Cloud Next 25, fueron muchos, pero en materia de hardware fueron pocos; sin embargo, no por eso, significa que no sea importante. La gran G presentó una nueva generación de su familia de Tensor Processing Units (TPU), diseñada exclusivamente para tareas de inferencia, llamada Ironwood.
Recordemos que las TPU son chips desarrollados por Google que ejecutan modelos de aprendizaje automático de manera muy eficiente, especialmente aquellos modelos con redes neuronales profundas.
Las TPU están pensadas para optimizar procesos de álgebra matricial, que son fundamentales en las tareas para el procesamiento de lenguaje natural y predicciones generativas.c
En cuanto al rendimiento, la nueva TPU de Google, Ironwood, marca una diferencia notable. Este nuevo chip no requiere un sistema de refrigeración líquida como sus antecesores, ni infraestructura de data center especializada. Esto permite una implementación sea más fácil y más eficiente desde el punto de vista de consumo de energía.
Su arquitectura se adapta a infraestructuras estándar, orientada a entornos donde se ejecutan modelos ya entrenados.
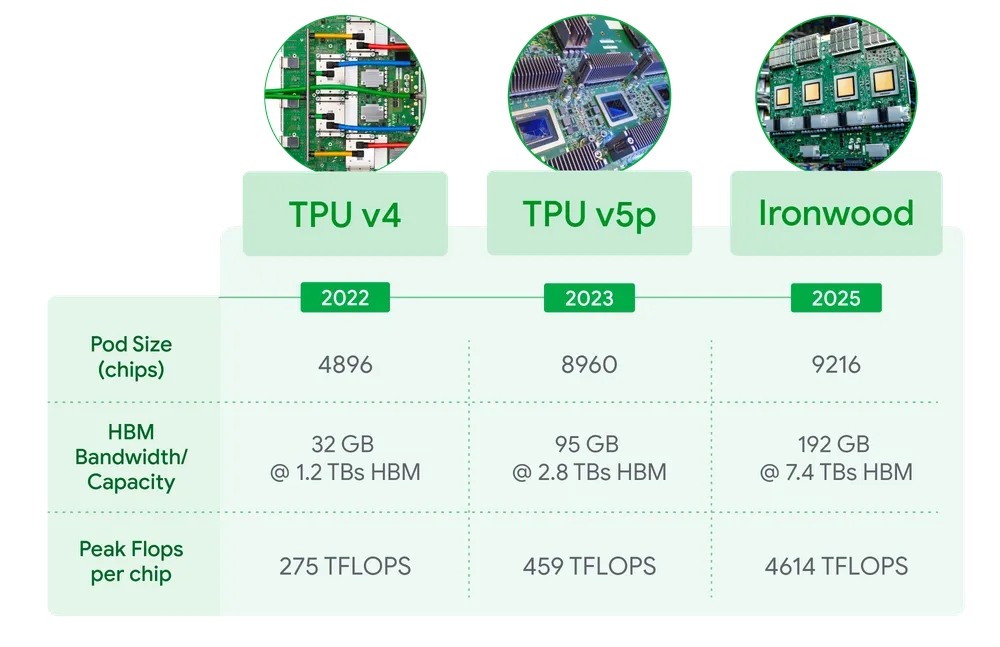
Al ver la tabla anterior, se observa que la configuración de pods en Ironwood alcanza hasta 9.216 chips, superando loa 8960 de la TPU v5p. En cuanto a la memoria, el crecimiento es exponencial con 192 GB de memoria tipo HBM, que tiene un ancho de banda de 7.4 TB/s.
Esta configuración del Inronwood, permite la ejecución de modelos de lenguajes más complejos, y permitir trabajos en paralelo y dar respuesta a múltiples clientes en simultáneo.
Uno de los datos más destacables es su rendimiento máximo por chip: 4.614 TFLOPS, una cifra muy superior a los 459 TFLOPS de v5p. Este aumento refleja la apuesta de Google por una aceleración profunda en tareas de inferencia, enfocándose en reducir la latencia y optimizar el uso energético.
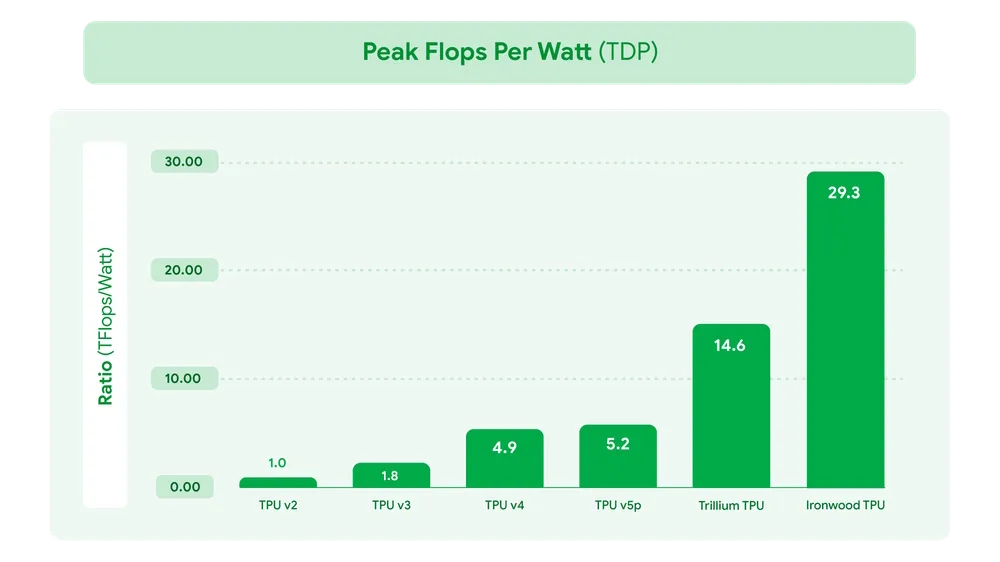
IIronwood no es la primera TPU de Google, pero sí representa la primera en enfocarse exclusivamente en la inferencia, ¿El camino escogido por Google será el correcto para el futuro del hardware de las IA?
Fuente: Google
