
Las fábricas de IA modernas exigen un nuevo enfoque arquitectónico, porque con la llegada de los modelos de IA agéntica y de las leyes de escalado en etapas de inferencia (test-time scaling), el procesador individual deja de ser el factor que marca el límite y la unidad real de cómputo pasa a ser el centro de datos en su conjunto, Bajo esa lógica, NVIDIA desarrolla su plataforma Vera Rubin, ideada a partir de un diseño extremo y coordinado (extreme co-design) que integra cómputo, redes y almacenamiento para operar como una única supercomputadora unificada.
Para entender cómo NVIDIA da este salto generacional y enfrenta los cuellos de botella de energía y ancho de banda a gran escala, conviene mirar su arquitectura modular, ya que Vera Rubin no se plantea como un servidor aislado, sino como una jerarquía de tres niveles estrechamente orquestados.
A continuación, se puede seguir ese recorrido desde el silicio base hasta los armarios de gran escala que sostendrán la infraestructura de próxima generación:
- Nivel 1 (los 7 chips base): representa el silicio puro. Son siete procesadores especializados que se dividen las cargas de entrenamiento, inferencia de baja latencia, almacenamiento y conectividad de red de altísima velocidad.
- Nivel 2 (las 6 bandejas o blades): son los módulos físicos de servidor, basados en la arquitectura estandarizada NVIDIA MGX. Aquí es donde los chips del nivel 1 se instalan y agrupan según su función.
- Nivel 3 (los 5 sistemas de rack): es el producto final. Son cinco armarios a escala completa que apilan e interconectan las bandejas del nivel 2. Al agruparse, forman un superordenador gigante capaz de manejar gigavatios de energía.
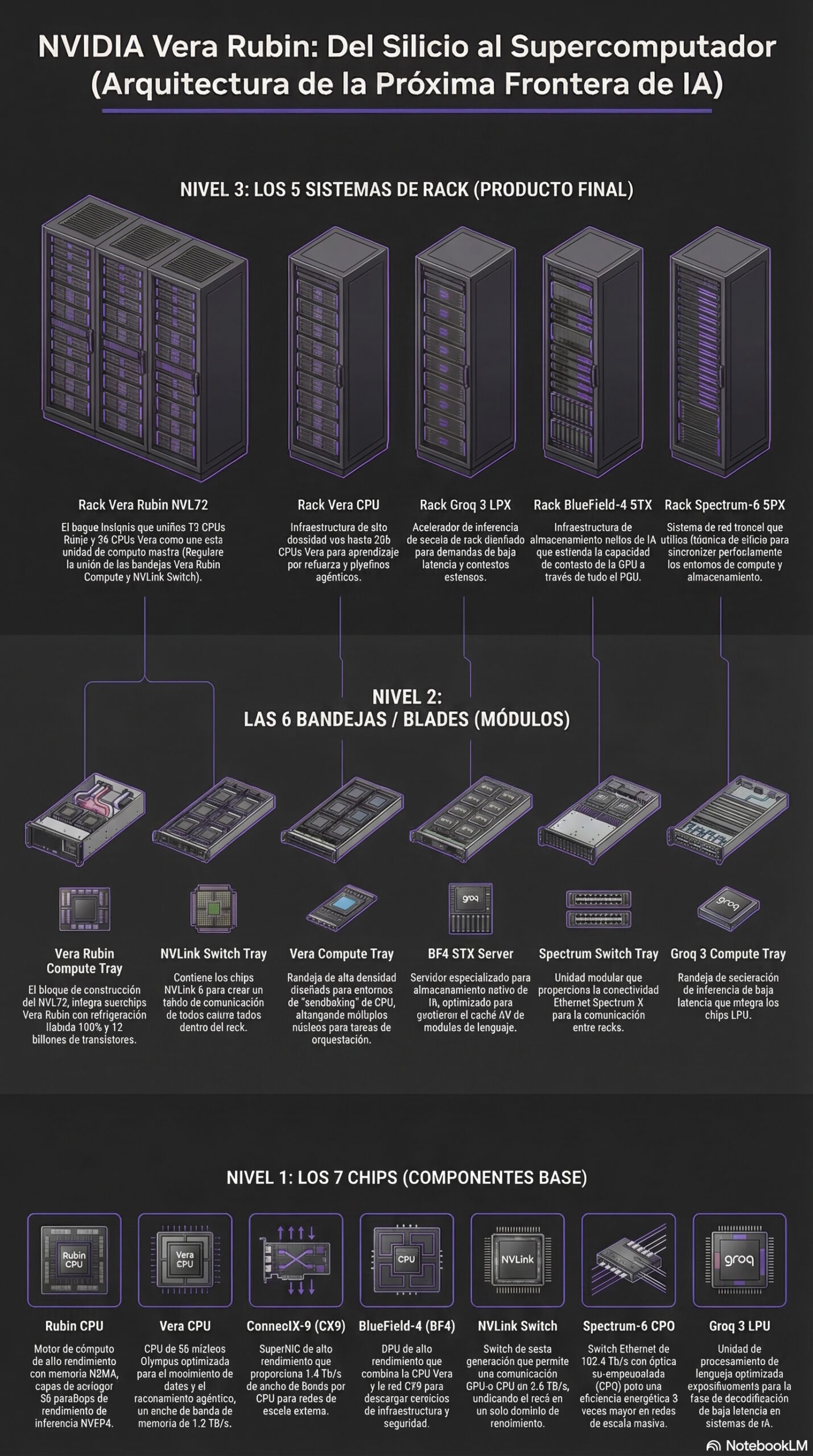
Nivel 1: los 7 chips base que forman los cimientos de NVIDIA Vera Rubin
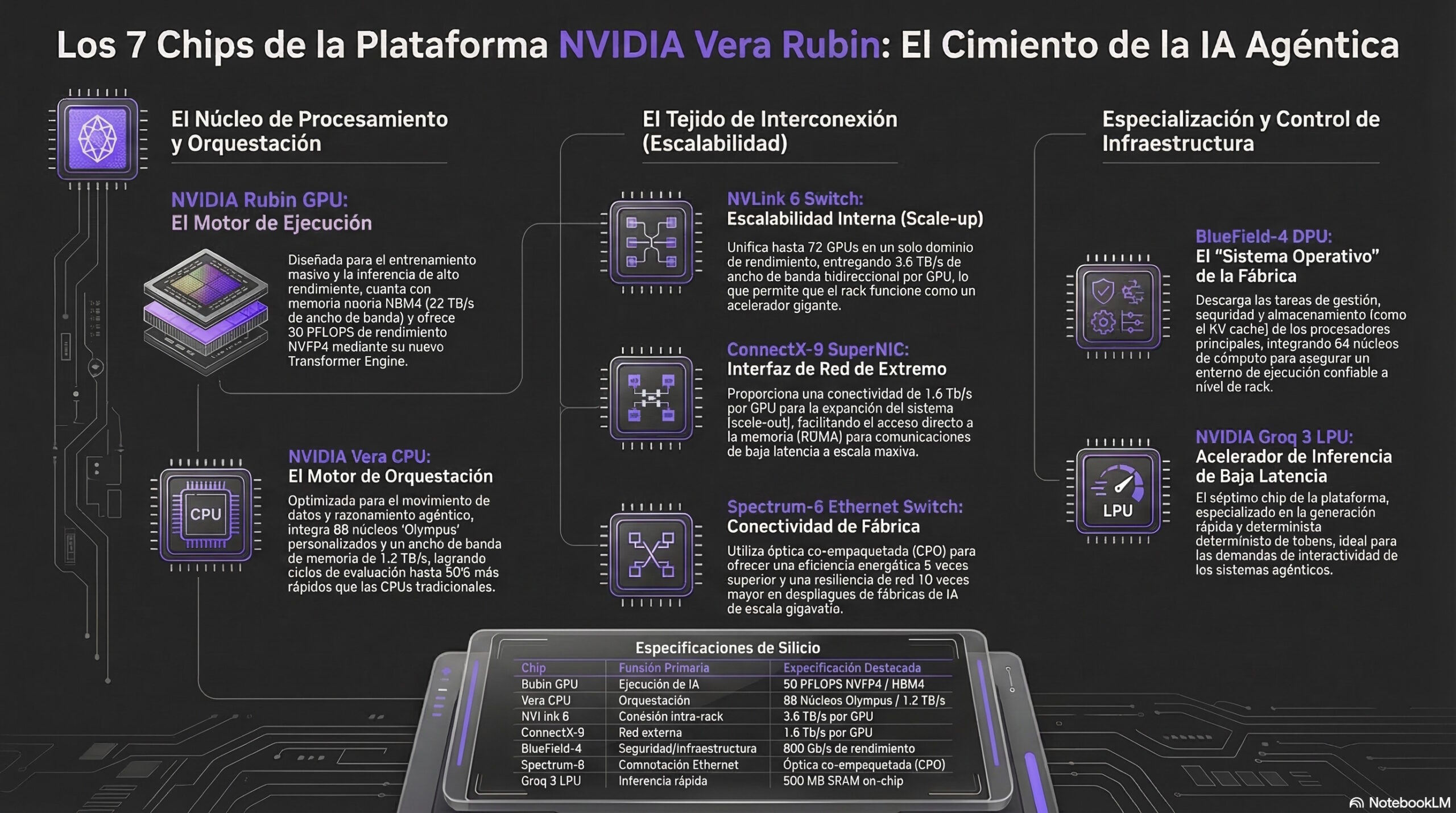
En lugar de depender de un solo procesador central multipropósito, la plataforma NVIDIA Vera Rubin distribuye las cargas de trabajo de la IA agéntica a través de un ecosistema de siete procesadores altamente especializados.
Este nivel base, el silicio fundamental, se compone de chips diseñados bajo una filosofía de “co-diseño extremo”, donde cada pieza está optimizada para resolver cuellos de botella muy específicos de computación, memoria o red dentro de las fábricas de IA.
Llevemos la idea de los 7 chips a algo más terrenal; imagina un restaurante de alta cocina con estrellas Michelin.
- En el pasado, un solo chef (el procesador tradicional) intentaba cocinar todos los platos, tomar los pedidos y limpiar las mesas.
- Hoy, la IA requiere un equipo de especialistas de élite trabajando en perfecta sincronía.
- Con esta premisa, NVIDIA plantea los siete chips fundamentales, cada uno diseñado obsesivamente para dominar una tarea específica.
El cerebro de la operación: procesamiento masivo y agénticos
En el corazón de la plataforma Vera Rubin se encuentra el núcleo computacional, dividido estratégicamente para manejar los dos mundos que la IA moderna exige:
- La fuerza bruta para digerir información a escala colosal
- La precisión lógica para tomar decisiones secuenciales.
GPU Rubin: el motor de cálculo masivo
Técnicamente, la GPU Rubin integra 224 multiprocesadores de transmisión (SMs) equipados con Tensor Cores de quinta generación, los cuales están profundamente optimizados para la ejecución de operaciones de baja precisión matemática, específicamente en formatos NVFP4 y FP8.
Cuenta con un motor Transformer de tercera generación capaz de alcanzar hasta 50 PetaFLOPS en NVFP4 durante las tareas de inferencia. Para evitar el estrangulamiento por falta de datos, la GPU Rubin da un salto adoptando la memoria HBM4, la cual duplica el ancho de la interfaz respecto a su predecesora (HBM3e) y casi triplica el ancho de banda general en comparación con la arquitectura Blackwell.

Sigamos con la analogía del restaurante, pero en este caso cuenta con un chef maestro de un restaurante de tres estrellas Michelin capaz de cocinar cientos de platos complejos simultáneamente. Su nueva memoria HBM4 es como tener una despensa infinita instalada directamente sobre su mesa de trabajo, permitiéndole tomar ingredientes sin dar un solo paso, cocinando a una velocidad industrial.
CPU Vera: el orquestador de datos
La CPU Vera es un procesador basado en 88 núcleos Arm personalizados que actúa como un motor de datos acoplado directamente a la ejecución de la GPU. En la IA moderna, especialmente con agentes autónomos que razonan paso a paso, las tareas secuenciales crean cuellos de botella severos (un problema conocido como la Ley de Amdahl).
Vera se encarga de mitigar esto, administrando el movimiento de datos, la planificación y la sincronización con muy baja latencia y utilizando memoria compartida, sin introducir la latencia típica de los procesadores anfitriones (hosts) tradicionales.

En el caso del restaurante, la CPU Vera se transforma en el gerente de operaciones del restaurante. Mientras el chef (la GPU) hace el trabajo pesado a gran velocidad, el gerente Vera coordina las comandas (órdenes o pedidos), organiza a los camareros y sincroniza los tiempos. Se asegura de que la cocina nunca se detenga por una mala planificación.

Velocidad y memoria: el fin de las esperas
Tener el procesador más potente del mundo no sirve de nada si el sistema sufre de amnesia a mitad de una tarea o si tarda demasiado en articular una respuesta. Esta dupla de chips (GPU y CPU) se encarga de que la interacción con la IA sea instantánea y que su memoria a corto plazo sea infalible.
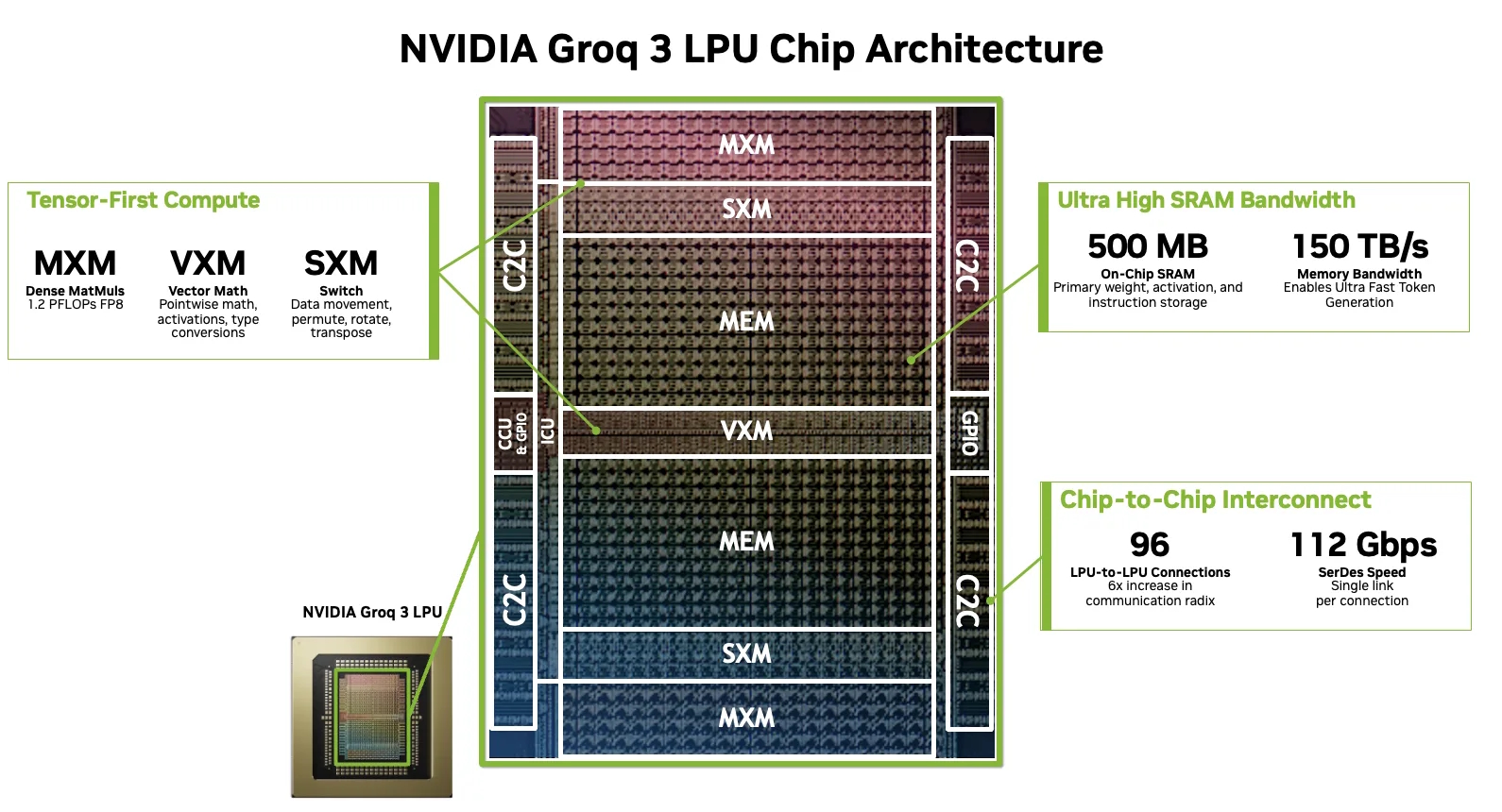
LPU Groq 3: Aceleración determinista de baja latencia
La Unidad de Procesamiento de Lenguaje (LPU) Groq 3 es un procesador de inferencia especializado en la fase de “decodificación” (generar tokens o palabras). Su arquitectura abandona el enfoque clásico de maximizar el rendimiento mediante procesamiento por lotes masivos, apostando por una ejecución completamente determinista y controlada por compilador.

Groq 3 opera con vectores de 320 bytes utilizando módulos de ejecución de matrices (MXM) y vectores (VXM), apoyado por un ancho de banda de memoria SRAM dentro del chip masivo (hasta 40 PB/s a nivel de rack). Esto garantiza que cada token generado tenga una latencia predecible y minúscula.
En el resturante:
- Si la GPU es el chef maestro capaz de procesar la receta de un banquete monumental en un segundo, el LPU Groq 3 es un mesero de velocidad sobrehumana.
- El trabajo de la LPU es ir entregando cada bocado (palabra) al comensal de manera instantánea y fluida, garantizando que el cliente nunca se quede mirando hacia la cocina con la mesa vacía.
DPU BlueField-4: gestión de memoria contextual (CMX)
La Unidad de Procesamiento de Datos BlueField-4 es el procesador que habilita la plataforma de Almacenamiento de Memoria Contextual (CMX). A medida que los modelos de IA mantienen conversaciones de millones de tokens, la “memoria a corto plazo” de la IA (llamada caché KV) se desborda y satura la costosa memoria de las GPUs.

Es por esto que BlueField-4 crea y gestiona un nuevo nivel de almacenamiento flash conectado por Ethernet (conocido como nivel G3.5). Esto permite precargar historiales enteros de conversación en la GPU de manera instantánea, evitando interrupciones en la decodificación y logrando mejoras de eficiencia energética de hasta 5 veces.
Siguiendo con el ejemplo del restaurante, BlueField-4 se transforma en el jefe de sala con memoria fotográfica del entorno. Cuando la IA necesita recordar un detalle exacto de una mesa que lleva horas pidiendo platos, el BlueField-4 saca esa comanda de un archivador ultrarrápido y se la entrega al chef (GPU) al instante, evitando que este tenga que repasar todo el libro de reservas desde cero.
El sistema logístico: conectividad y autopistas de datos de NVIDIA Vera Rubin
Incluso los componentes más rápidos del planeta se detendrían si no pueden intercambiar información al instante. Para evitar los cuellos de botella, NVIDIA diseñó una infraestructura de red que mueve los datos tanto dentro del servidor como hacia el exterior a velocidades vertiginosas.
ConnectX-9 (CX9): interfaz de red de ultra alta velocidad
El SuperNIC ConnectX-9 es una tarjeta de interfaz de red (NIC) de próxima generación que soporta velocidades de hasta 1600G. Está diseñado específicamente para el escalamiento horizontal (scale-out) a través de la red del centro de datos, garantizando que un ancho de banda masivo permita que los estados de los modelos y los flujos de datos puedan entrar y salir de los servidores hacia otras áreas de la fábrica de IA con una latencia insignificante.

Llevando esto a la dinámica de nuestro restaurante de alta cocina, imagina el ConnectX-9 como la gigantesca puerta de carga y descarga del local. En este escenario logístico:
- Esta tarjeta garantiza que esos accesos logísticos sean inmensos, permitiendo que el tráfico fluya constantemente y sin el más mínimo embotellamiento.
- Si la puerta de servicio es estrecha, los camiones con ingredientes frescos (datos) se atascarán afuera, sin importar qué tan rápido cocine el chef (la GPU).
- Con un atasco en la entrada, los pedidos terminados tampoco podrán salir a tiempo hacia el comedor.
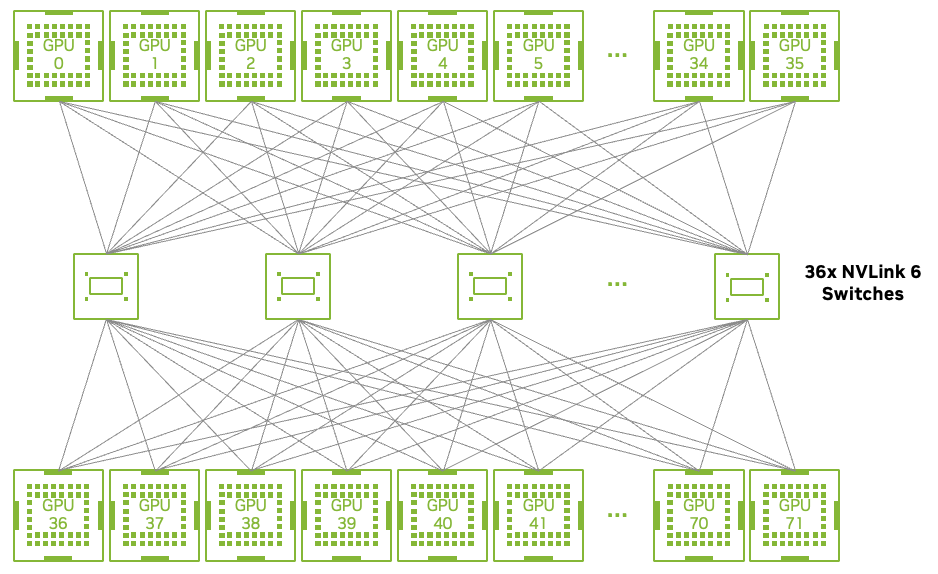
NVLink Switch: la columna vertebral interconectada
El NVLink Switch de sexta generación es el puente de comunicación interno del sistema, capaz de mover datos a 3600 GB/s. En lugar de usar redes tradicionales de servidor a servidor, este conmutador conecta físicamente decenas de GPUs dentro del mismo rack (escalamiento vertical o scale-up). Esto permite que el tejido de procesadores comparta memoria y datos de forma tan nativa que la red entera se comporta lógicamente como una sola macro-GPU gigante.

Siguiendo con la analogía culinaria, el NVLink Switch funciona como un sistema de comunicación instantánea, casi telepática, dentro de la misma cocina. En lugar de que los chefs se griten las comandas de una estación a otra, este conmutador permite lo siguiente:
- Logra que todos trabajen en perfecta sincronía, exactamente como si fueran un solo chef gigante de cien brazos.
- Conecta directamente a decenas de cocineros en tiempo real.
- Facilita que compartan utensilios e ingredientes con precisión absoluta sin estorbarse.
Spectrum CPO: la autopista fotónica
El chip Spectrum CPO integra la óptica empaquetada (Silicon Photonics) directamente en el equipo de red (Spectrum-6), ofreciendo una capacidad de conmutación abrumadora de hasta 102T. Al usar luz (fotones) en lugar de electricidad para mover la información a grandes distancias, proporciona una conectividad Ethernet resiliente, de baja latencia y altísimo ancho de banda para enlazar todos los armarios del centro de datos entre sí.

Para entender la escala de este último chip dentro de nuestro ejemplo, piensa que si el NVLink Switch asegura la comunicación perfecta dentro de un solo restaurante, el Spectrum CPO lleva esto a un nivel masivo. Funciona como una red de tubos neumáticos a la velocidad de la luz que:
- Hace que todas las sucursales operen en conjunto como un único e inmenso imperio culinario (el centro de datos unificado).
- Conecta a cientos de sucursales distintas de este restaurante (los diferentes racks).
- Permite que todos los locales intercambien recetas y recursos al instante, sin importar la distancia.
Nivel 2: El músculo modular a través de las 6 bandejas (Blades)
Para que los chips del Nivel 1 reciban energía, refrigeración y puedan comunicarse, necesitan ser empaquetados en placas base físicas. NVIDIA ha estandarizado este proceso mediante una arquitectura llamada MGX, que permite crear bandejas o servidores modulares diseñados para integrarse en armarios a gran escala.

Estas bandejas se caracterizan por emplear refrigeración líquida directa a 45 grados Celsius, prescindir de marañas de cables internos mediante conexiones directas en el chasis (busbar) y permitir el reemplazo de piezas de forma rápida. En este nivel, los componentes se agrupan en seis diseños diferentes, cada uno con un propósito vital en la fábrica de IA.

Vera Rubin Compute Tray: el bloque de construcción maestro
Esta bandeja es el corazón computacional del sistema, ya que integra físicamente las GPUs Rubin y las CPUs Vera, entrelazándolas con conexiones ultrarrápidas NVLink-C2C para garantizar que los procesadores se mantengan alimentados de datos sin cuellos de botella.



Cuenta con un diseño modular, está cien por ciento refrigerado por líquido y carece de cableado complejo, lo que facilita enormemente su manufactura y mantenimiento en los centros de datos.
Analogía con el restaurante del Vera Rubin Compute Tray
Llevando esto a la dinámica del restaurante, esta bandeja actuaría como la estación de cocina industrial prefabricada en acero inoxidable:
- Ya trae los fogones de ultra alta temperatura (las GPUs) y el escritorio del gerente (la CPU) perfectamente ensamblados.
- No hay cables ni tuberías sueltas con las que el equipo de cocina pueda tropezar.
- Los instaladores simplemente la deslizan en su lugar, conectan el suministro de agua fría y en minutos está lista para preparar los banquetes más complejos.

NVLink Switch Tray: el nudo de comunicación resiliente
Para que múltiples bandejas de cómputo trabajen en un mismo modelo de IA al mismo tiempo, necesitan compartir datos a velocidades extremas. Para ello se requiere la bandeja (blade) que contiene los chips NVLink de sexta generación que hacen esto posible.

Su innovación más crítica es la resiliencia operativa, es decir, está pensada para poder ser extraída y reemplazada por un técnico en caliente, lo que significa que se puede cambiar mientras el armario sigue funcionando, sin interrumpir los entrenamientos gracias al enrutamiento dinámico de tráfico.
Siguiendo con la analogía del restaurante, este blade funciona como la cinta transportadora de alta velocidad que conecta a todas las estaciones de los chefs:
- Los cocineros pueden pasarse ingredientes al instante y trabajar como un equipo unificado.
- Su diseño es tan avanzado que, si un tramo de la cinta se atasca, un mecánico puede extraer la pieza entera y poner una nueva.
- Todo este mantenimiento ocurre sin apagar nada, evitando que la cocina se detenga o se retrase una sola orden.
Vera Compute Tray: la granja de razonamiento y preparación
A medida que la IA adopta modelos agénticos que razonan y usan herramientas, las tareas secuenciales pueden crear embotellamientos severos. Esta bandeja está dedicada exclusivamente a resolver ese problema, agrupando CPUs Vera con un subsistema de memoria de muy bajo consumo que entrega hasta 1.2 TB/s de ancho de banda.

Su función es ejecutar el aprendizaje por refuerzo, evaluar resultados y compilar código en bucles de retroalimentación sin ocupar el valioso tiempo de las GPUs.
En nuestro restaurante tecnológico, sería como una gigantesca cocina de preparación y área de investigación separada del caos principal:
- No se cocinan los platos fuertes, sino que miles de asistentes (agentes) pican ingredientes y evalúan nuevas recetas.
- Buscan información en manuales y organizan los tiempos de forma simultánea.
- Todo este trabajo minucioso y de fondo se realiza aquí para que los chefs maestros (GPUs) se dediquen exclusivamente a la alta cocina.
Groq 3 Compute Tray: el motor determinista de baja latencia
Diseñada para la inferencia donde el tiempo de respuesta es crítico, esta bandeja alberga los aceleradores Groq 3. Para evitar los retrasos comunes en la generación de palabras (tokens), utiliza memoria SRAM ultrarrápida integrada directamente en los chips logra un ancho de banda de 1.2 PB/s con respecto a la bandeja.

Esta arquitectura prioriza la ejecución determinista, garantizando que cada token generado tenga una latencia predecible y minúscula.
Desde el punto de vista del ejemplo del restaurante, para los clientes que no tienen tiempo, esta bandeja es la ventanilla de servicio rápido y emplatado exprés adosada a la cocina central. Su especialidad es la inmediatez:
- Toma el control cuando un cliente pide respuestas inmediatas en lugar de un menú de degustación largo.
- Emplata y entrega cada bocado (palabra) de forma extremadamente veloz y coreografiada.
- Garantiza un ritmo tan fluido que el comensal jamás experimenta un solo segundo de espera con el plato vacío.
Servidor BlueField-4 STX: el archivo de memoria a largo plazo
Esta blade da vida a la plataforma de almacenamiento de Memoria Contextual (CMX), resolviendo el problema de las conversaciones de IA que duran millones de palabras. Establece un nuevo nivel de memoria que utiliza almacenamiento flash ultrarrápido conectado por red para guardar el caché de contexto.
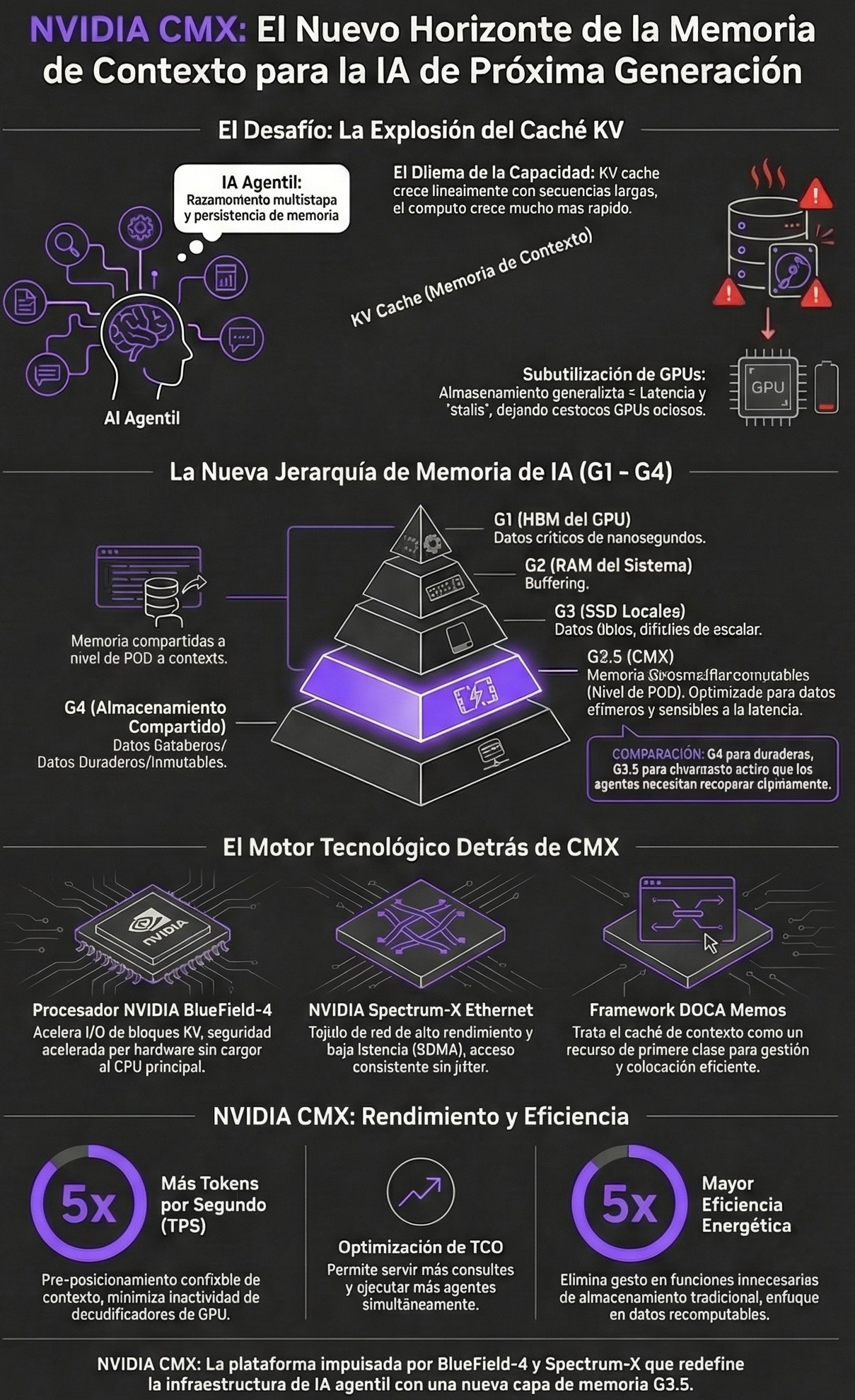
Al actuar como la memoria a largo plazo, libera la costosa y limitada memoria principal de las GPUs, permitiendo reutilizar el historial de los usuarios de manera eficiente.

Para no saturar el espacio de trabajo principal, este servidor actúa como el enorme archivo subterráneo del restaurante, es decir:
- Evita que el chef ocupe su valiosa mesa de trabajo guardando los pesados libros de reservas y preferencias de los comensales.
- Almacena todos esos historiales en estanterías ultrarrápidas de fácil acceso.
- Cuando el chef necesita recordar una alergia específica, el archivo le envía el expediente exacto por un tubo neumático de forma instantánea.
Spectrum Switch Tray: el distribuidor fotónico
Esta última bandeja es un conmutador basado en el chip Spectrum CPO, encargado de conectar múltiples armarios y centros de datos entre sí.
Su característica principal es la fotónica co-empaquetada, la cual utiliza luz para transmitir información, reduciendo la pérdida de señal y mejorando su integridad. Está diseñado específicamente para soportar el tráfico masivo que se genera cuando las fábricas de IA intercambian datos a escala global.


Finalmente, para entender la importancia de esta pieza de ingeniería, sería la torre de control de logística externa del imperio gastronómico. Su labor es puramente de coordinación exterior:
- Controla las flotas de camiones y aviones de carga (fotones de luz) que transportan los ingredientes para los restaurantes hacia otras ciudades (que son los racks).
- Garantiza, con absoluta precisión, que ninguna carretera externa se congestione.
- Asegura que todas las sucursales del restaurante a nivel global operen de manera sincronizada y sin retrasos en las entregas.
Topología multiplano de NVIDIA Spectrum-X, diseñada para escalar redes Ethernet de IA en una arquitectura plana de dos nivele

Nivel 3: los 5 sistemas de rack
Si los chips del Nivel 1 eran nuestro personal de élite y las bandejas modulares del Nivel 2 representaban sus estaciones de trabajo integradas, los sistemas de rack son los edificios completos.

Al apilar y conectar estas bandejas en armarios estandarizados basados en la arquitectura NVIDIA MGX, se crean instalaciones masivas con propósitos muy definidos. Cuando múltiples racks se enlazan entre sí, forman lo que NVIDIA denomina un SuperPOD: un gigantesco complejo industrial o “fábrica de IA” capaz de procesar y razonar a una escala sin precedentes.

Rack Vera Rubin NVL72
Este es el superordenador insignia y el motor de cálculo principal de la fábrica de IA. Para construir este coloso, se apilan y entrelazan estratégicamente dos tipos de bandejas del nivel anterior: las de cómputo Vera Rubin y las de conmutación NVLink Switch.
Esta integración permite que 72 GPUs Rubin y 36 CPUs Vera se comuniquen a través de una inmensa espina dorsal de cobre que ofrece 260 TB/s de ancho de banda, comportándose lógicamente como una sola GPU gigante.
A nivel técnico, este rack ofrece hasta 3.6 exaFLOPS de rendimiento en inferencia NVFP4 y está diseñado específicamente para soportar las leyes de escalado de la IA moderna, logrando una eficiencia 10 veces mayor por vatio que la generación anterior. Todo el sistema opera bajo refrigeración líquida directa a 45 grados Celsius, maximizando la eficiencia energética.

Llevando esto a la escala de nuestro imperio gastronómico (cadenas de restaurante), este rack es el edificio principal y el corazón de nuestro restaurante de tres estrellas Michelin:
- En lugar de tener 72 cocinas aisladas, hemos derribado todas las paredes para unir a los 72 chefs maestros.
- Se conectan mediante un sistema de comunicación instantánea que evita cualquier retraso en las comandas.
- Todos se mueven, cocinan y piensan como si compartieran un solo cerebro gigante, elaborando los banquetes más complejos en una fracción del tiempo.
La imagen de NVIDIA Dynamo muestra cómo se distribuye el trabajo dentro de una arquitectura heterogénea de inferencia. En ese esquema, Vera Rubin NVL72 se encarga del prefill y de la atención sobre el KV cache, mientras Groq 3 LPX asume la etapa de decode vinculada a la generación de tokens.
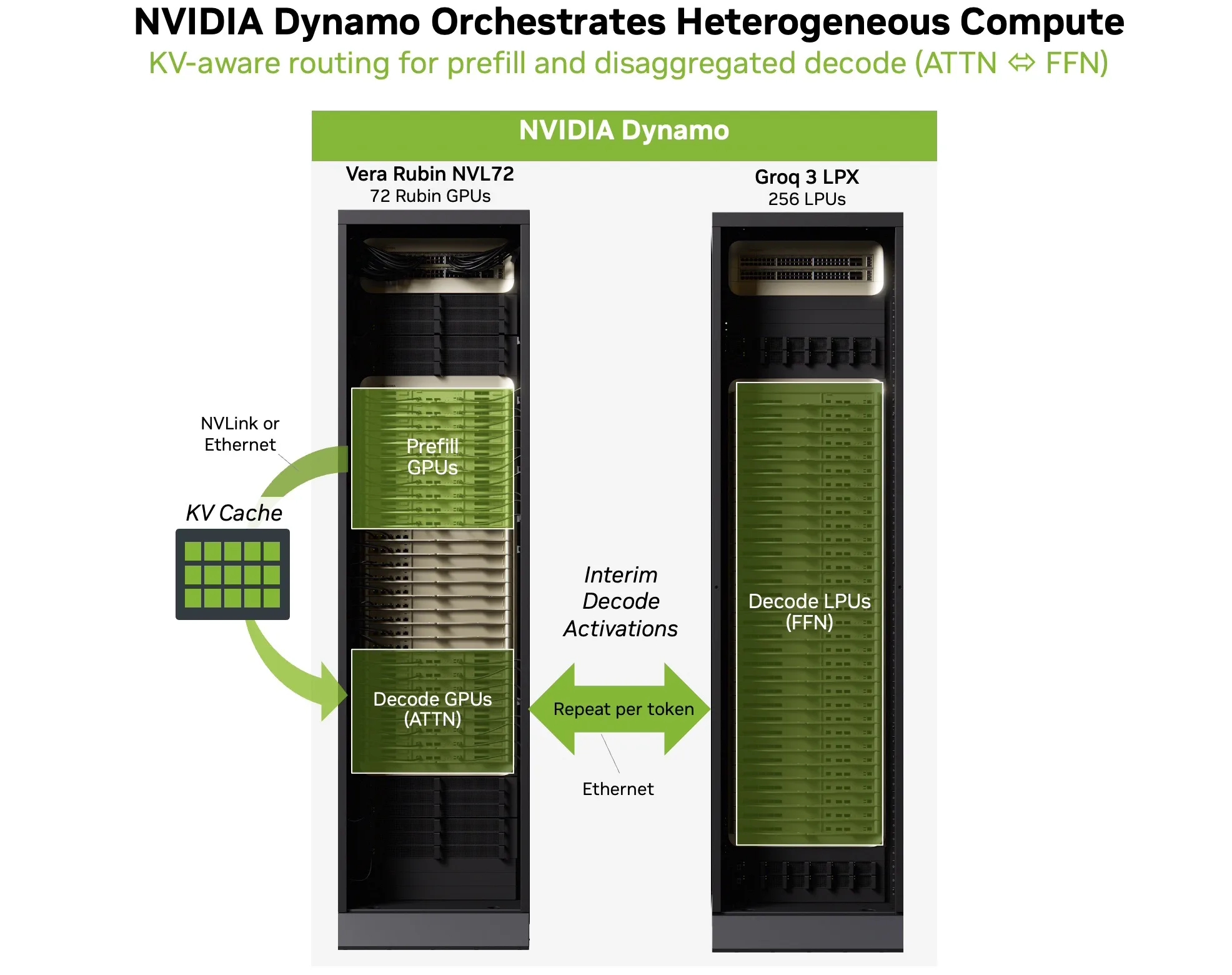
Bajo esa lógica, el rack que se presenta a continuación corresponde justamente a ese segundo bloque del diagrama. Es decir, al sistema especializado que toma el relevo tras el procesamiento inicial del contexto para ejecutar la fase de decodificación con la menor latencia posible.
Rack Groq 3 LPX: el servicio de entrega exprés
Este rack está diseñado para resolver el problema de latencia en sistemas de IA interactivos y agénticos; este rack integra 256 aceleradores Groq 3. En lugar de depender de la costosa memoria HBM, este armario cuenta con 128 GB de memoria SRAM integrada directamente en los chips, logrando un ancho de banda masivo de 40 PB/s a nivel de rack.

Su propósito es trabajar de forma heterogénea junto al NVL72. Mientras las GPUs Rubin procesan el inmenso contexto inicial, el rack LPX toma el relevo en la fase de “decodificación” para generar las palabras a una velocidad extrema. Esta combinación dispara el rendimiento de inferencia para modelos gigantescos.

Siguiendo con la analogía de los restaurantes, este rack es como el ala de despacho ultrarrápido o el drive-thru hipereficiente adosado a la cocina central. Su especialidad es la inmediatez:
- Cuando un cliente VIP requiere respuestas y bocadillos al instante en lugar de esperar un menú de degustación completo, esta estación toma el control.
- Un equipo de 256 especialistas en velocidad extrema se encarga exclusivamente de esta tarea.
- Empaquetan y entregan cada bocado en fracciones de segundo, garantizando que el usuario jamás tenga que esperar con el plato vacío.
Vera CPU Rack: la granja de razonamiento y preparación
El entrenamiento de IA moderna (especialmente el aprendizaje por refuerzo) exige evaluar millones de escenarios y ejecutar código de forma autónoma. Para ello, el Vera CPU Rack agrupa hasta 256 procesadores Vera refrigerados por líquido en un solo armario superdenso.
Este sistema es capaz de sostener más de 22.500 entornos concurrentes (“sandboxes”) para agentes de IA, operando de manera independiente. Al ofrecer un rendimiento de un solo hilo en la industria y un ancho de banda masivo, este rack completa ciclos de evaluación hasta un 50% más rápido y con el doble de eficiencia que la infraestructura tradicional.

Para no saturar el edificio principal de la cadena de restaurantes, este rack actúa como un inmenso anexo dedicado exclusivamente a la investigación y el trabajo de preparación (I+D):
- No se cocinan los platos principales, sino que miles de asistentes virtuales evalúan nuevas recetas y organizan los procesos.
- Buscan ingredientes de forma autónoma y hacen cálculos matemáticos en simultáneo.
- Realizan todo el trabajo secuencial y de fondo para entregarle las cosas listas y sin fricciones a los chefs maestros (las GPUs).
Rack BlueField-4 STX: la gran biblioteca de clientes
Este rack es la respuesta al desafío del almacenamiento en la era de los agentes autónomos, introduciendo la plataforma de Almacenamiento de Memoria Contextual (CMX). A medida que los modelos razonan sobre millones de palabras, la “memoria a corto plazo” termina por saturar a las GPUs.
Para evitarlo, el STX Rack, impulsado por el procesador BlueField-4, crea un nuevo nivel de memoria compartida en red basado en almacenamiento flash. Su función es descargar ese caché de las GPUs para que el contexto pueda ser reutilizado en múltiples sesiones, logrando hasta 5 veces más tokens por segundo y una eficiencia energética superior.

A nivel masivo, este rack actúa como el archivo histórico central de todo el imperio gastronómico. Su función es ser la memoria a largo plazo:
- Almacena registros ultradetallados de las conversaciones, alergias y gustos de millones de clientes pasados.
- Evita que los chefs tengan que saturar su mesa de trabajo buscando en expedientes antiguos cuando un comensal regresa.
- Localiza el registro exacto y se lo envía por un tubo neumático directo a sus manos en el milisegundo exacto en que lo necesitan.
Rack Spectrum-6 SPX: el centro logístico global
Para que la fábrica de IA funcione, todos estos armarios deben comunicarse entre sí y con el mundo exterior. El rack Spectrum-6 SPX asume ese rol como la columna vertebral de red que agrupa conmutadores Ethernet de altísima capacidad.
Su mayor innovación es el uso de óptica co-empaquetada (fotónica de silicio), que convierte los datos eléctricos en luz directamente en el chip. Esto elimina los transceptores enchufables tradicionales, brindando una latencia extremadamente baja y una inmensa resiliencia para sincronizar el tráfico masivo de los clústeres de IA.
Finalmente, para que todo el imperio funcione en perfecta sincronía, este rack representa la torre de control logístico de la compañía. Su rol de coordinación externa asegura que:
- Una inmensa flota de camiones y aviones (que viajan literalmente a la velocidad de la luz usando fotones) transporta los ingredientes y las órdenes terminadas.
- Se conecten de forma impecable todos nuestros distintos edificios y sucursales globales.
- Nunca haya un solo atasco en las carreteras del centro de datos, garantizando entregas internacionales sin un milisegundo de retraso.
