

La IA hoy en día está en todas partes, desde tu propio smartphone, el televisor, o la misma lavadora; de hecho, hasta las mismas redes de telefonía son gestionadas por IA. Este crecimiento implica que los modelos no solo deban ser potentes, sino que además estén diseñados con privacidad diferencial, lo que asegura que la información sensible quede protegida desde el inicio.
Con ese objetivo, Google Research presentó VaultGemma, un modelo de lenguaje de gran escala (LLM) entrenado desde cero con privacidad diferencial (DP, por sus siglas en inglés). Este enfoque marca un cambio importante, porque asegura que el modelo procese datos sin exponer detalles sensibles ni memorizar ejemplos específicos.
¿Qué es y cómo funciona la privacidad diferencial en modelos de lenguaje?
La privacidad diferencial es una técnica que agrega un ruido matemático, una especie de constante, al modelo cuando realiza cálculos mientras es entrenada. La idea que plantea Google, es que con este subterfugio matemático, es disfrazar la información, de modo que no pueda ser rastreable un dato particular de la data inicial.
Entendamos la idea con este ejemplo: hay un coro de personas cantando (data inicial) y, desde luego, cada persona tiene un timbre único que representaría un dato particular. Lo que propone la gran G, es incorporar un leve ruido a cada voz, de modo que no sea factible reconocer la voz de cada cantante; sin embargo, el resultado final del grupo (coro cantando), transmite la esencia de la canción sin exponer quién cantó qué nota.
Con esto es factible garantizar que las respuestas que da el modelo, no muestre información delicada a partir de lo que aprendió al ser entrenada.
Por otra parte, esta técnica tiene dos problemas:
- Exige más recursos de cómputo
- Mayores lotes de datos más grandes
Esto se puede comparar con atender una videollamada en un café lleno de gente. Es posible seguir la conversación, pero el ruido obliga a concentrarse más y demanda un esfuerzo adicional para lograrlo.
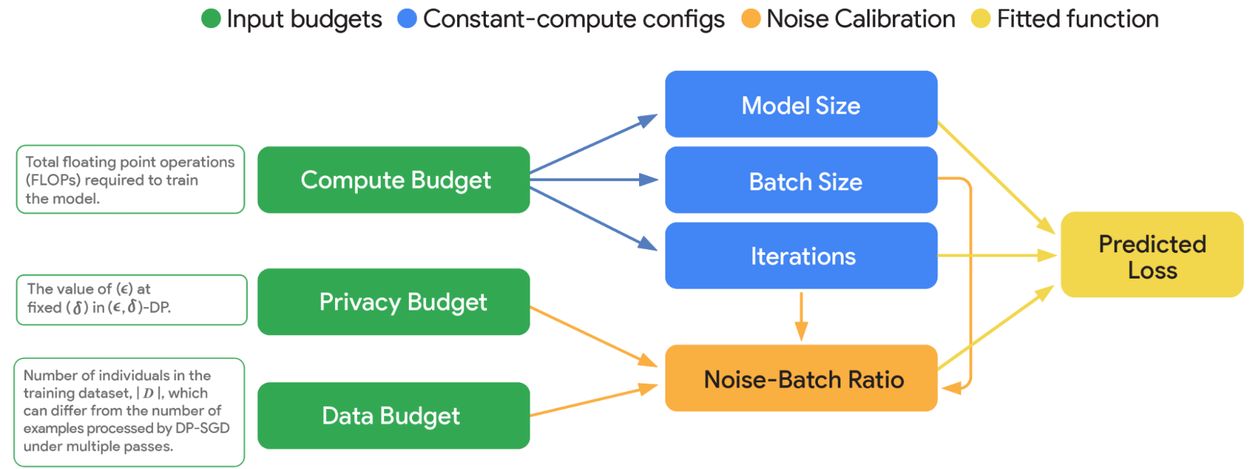
Escalamiento: cómo influyen el cómputo, los datos y la privacidad
Los investigadores desarrollaron leyes de escalamiento para entender cómo se relacionan tres elementos en el entrenamiento de modelos con privacidad diferencial:
- Cómputo disponible,
- Cantidad de datos
- El nivel de privacidad aplicado.
Dentro de este marco aparece la relación ruido-lote, un concepto central que mide cuánto y cómo el ruido agregado en comparación con el tamaño de los lotes de datos. Sus efectos se pueden resumir así:
- Con lotes pequeños, el ruido domina el aprendizaje y el modelo tiene más dificultad para captar patrones.
- Con lotes grandes, el ruido se diluye y el modelo logra identificar regularidades con mayor claridad.
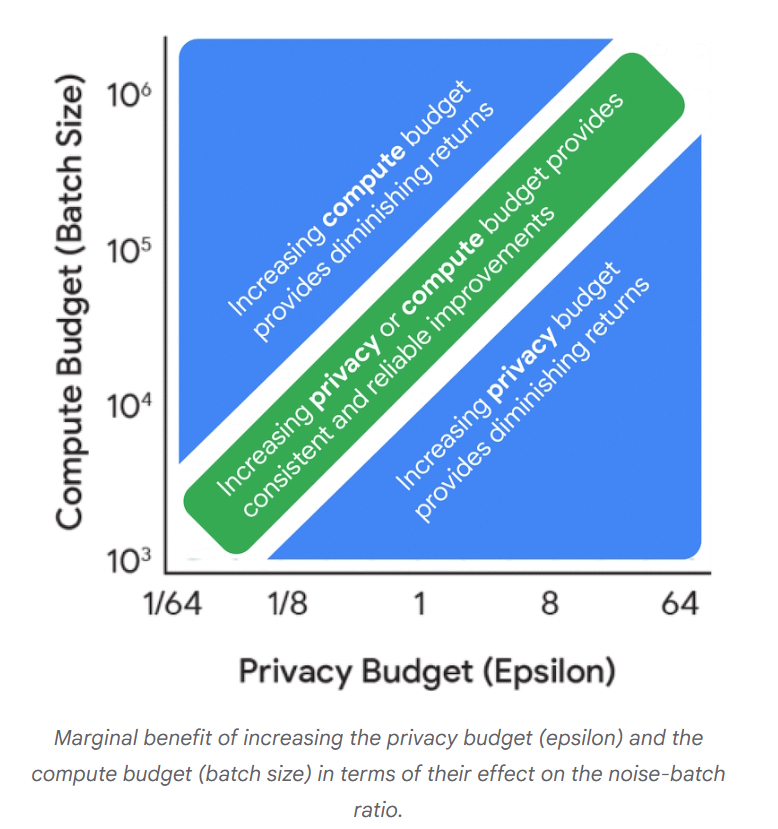
Imagina que tiene un vaso y un gran balde con agua, ¿qué ocurre con el sabor del agua en cada caso al verterle una cucharadita de sal a cada uno?
- El sabor del vaso con agua, lo más probable es que sea salado.
- En el caso del balde, al ser tan grande, esa cuchara no le va a cambiar el sabor.
Si llevamos esta idea al entrenamiento de los LLM al agregar un pequeño ruido (sal) a un conjunto de datos por lotes (balde con agua), no debería verse afectado, controlando el impacto del ruido en el entrenamiento.
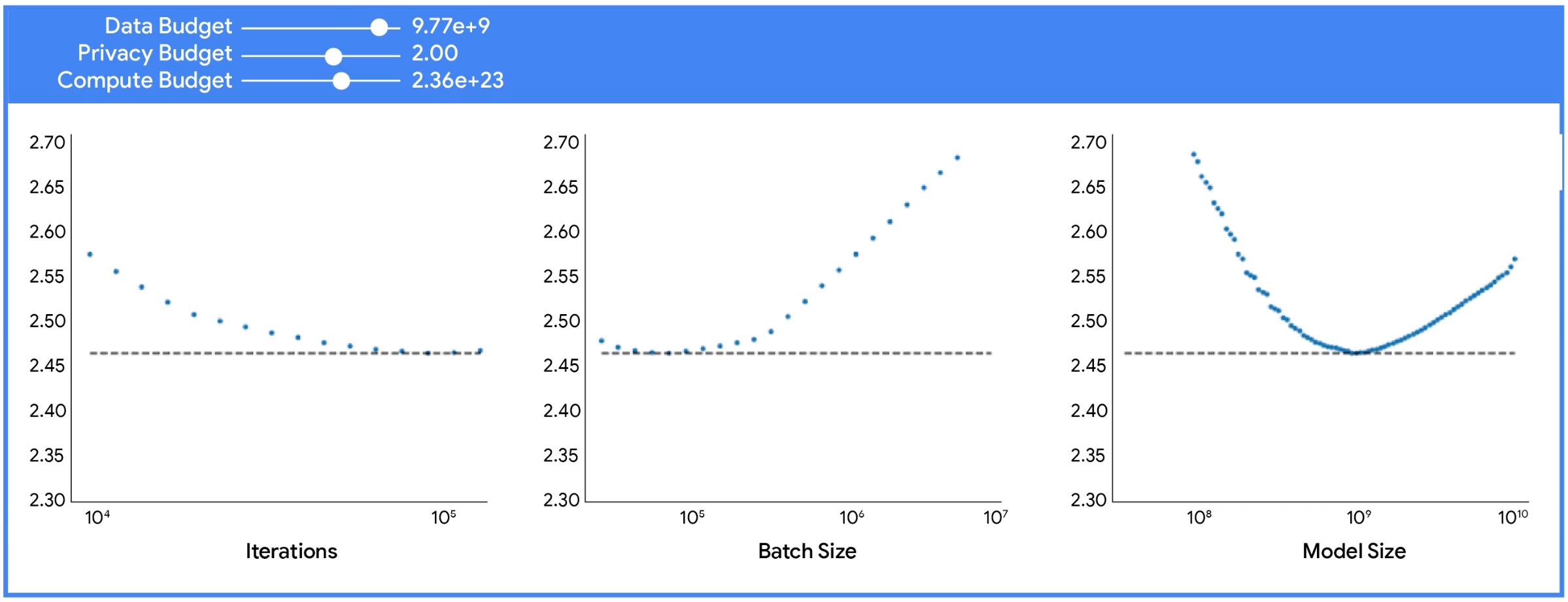
Configuraciones óptimas, resultados prácticos y rendimiento comparativo
Los experimentos mostraron que entrenar con privacidad diferencial requiere ajustar prioridades:
- No conviene centrarse en aumentar el tamaño del modelo.
- Lo más eficiente es usar un modelo más pequeño con lotes mucho más grandes.
- Este enfoque equilibra mejor los recursos y compensa la interferencia del ruido agregado.
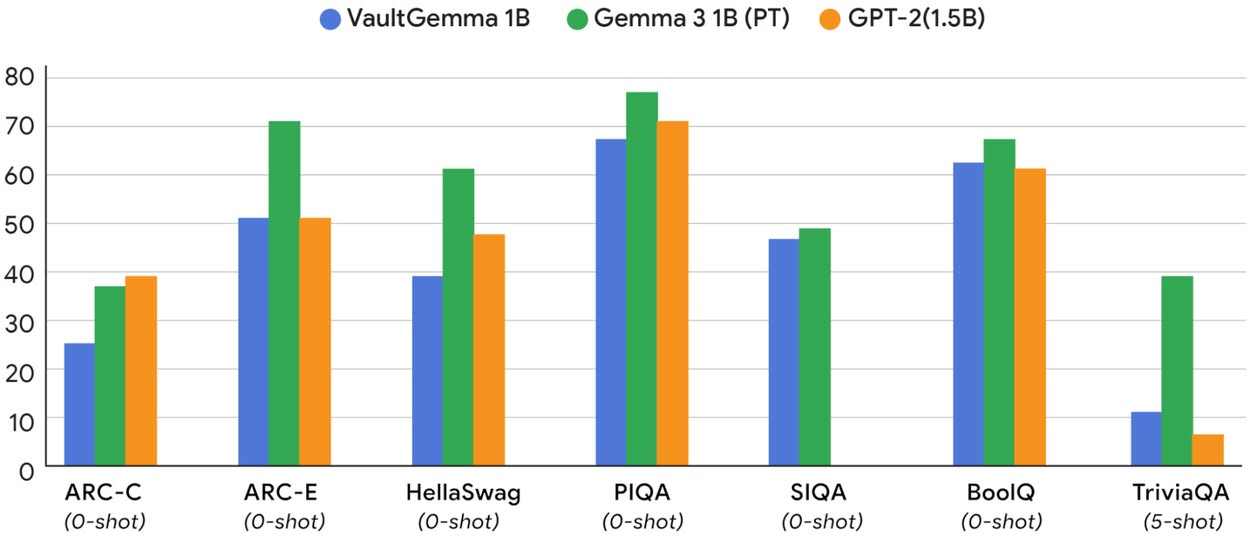
VaultGemma fue evaluado frente a otros modelos y los resultados arrojaron lo siguiente:
- Su contraparte no privada, Gemma3 1B, tuvo un rendimiento muy parecido.
- Frente al modelo más antiguo GPT-2 1.5B, VaultGemma mostró una utilidad equivalente a la de modelos no privados de hace cinco años.
- Estos hallazgos validan que la privacidad diferencial puede aplicarse sin eliminar la utilidad práctica de los modelos.
Con estos números, se puede suponer que VaultGemma logra un equilibrio: mantiene niveles de rendimiento cercanos a modelos no privados de años anteriores, pero con certezas claras en cuanto a seguridad de datos.
Conclusiones del estudio
El desarrollo de VaultGemma permite extraer varios aprendizajes:
- Es posible entrenar modelos grandes con privacidad diferencial sin perder toda su utilidad práctica.
- El modelo alcanza un rendimiento comparable a modelos no privados de hace cinco años.
- Se confirma que los lotes grandes y modelos más pequeños son más eficientes en contextos con privacidad diferencial.
- Los resultados validan las leyes de escalamiento propuestas, que orientan la distribución de recursos de cómputo, datos y privacidad.
- Aún existe una brecha de rendimiento frente a los modelos no privados más recientes, pero la investigación muestra un camino para reducirla.
- VaultGemma establece una base sólida para futuros sistemas que busquen combinar potencia, seguridad y respeto por los datos.
