
TRUEBench es un benchmark desarrollado y liberado por Samsung Research que busca medir la productividad de los modelos de lenguaje de IA en escenarios de uso laboral y usos cotidianos.
El benchmark de Samsung analiza el comportamiento de cada IA en tareas prácticas, midiendo las competencias de cada IA en diferentes tareas típicas.
Para la evaluación de modelos de lenguaje existen benchmarks muy usados, que tienen diferentes enfoques como:
- MMLU (Massive Multitask Language Understanding): mide conocimiento general en más de 50 disciplinas, con preguntas de opción múltiple. [
- BIG-bench: colección de tareas de razonamiento, matemáticas y conocimiento general, diseñada de manera colaborativa.
- HellaSwag: prueba la capacidad de un modelo para completar narrativas y evaluar razonamiento de sentido común.
- ARC (AI2 Reasoning Challenge): centrado en preguntas de ciencias a nivel escolar, busca medir razonamiento más que memoria. [
- MT-Bench: enfocado en conversaciones multi-turno, evalúa calidad de diálogos y consistencia de respuestas.
Todos los benchmark citados priorizan comprensión académica, conocimiento general o coherencia conversacional; por su parte, TRUEBench analiza cómo un modelo rinde en escenarios prácticos de trabajo.
¿Qué mide TRUEBench y por qué es distinto?
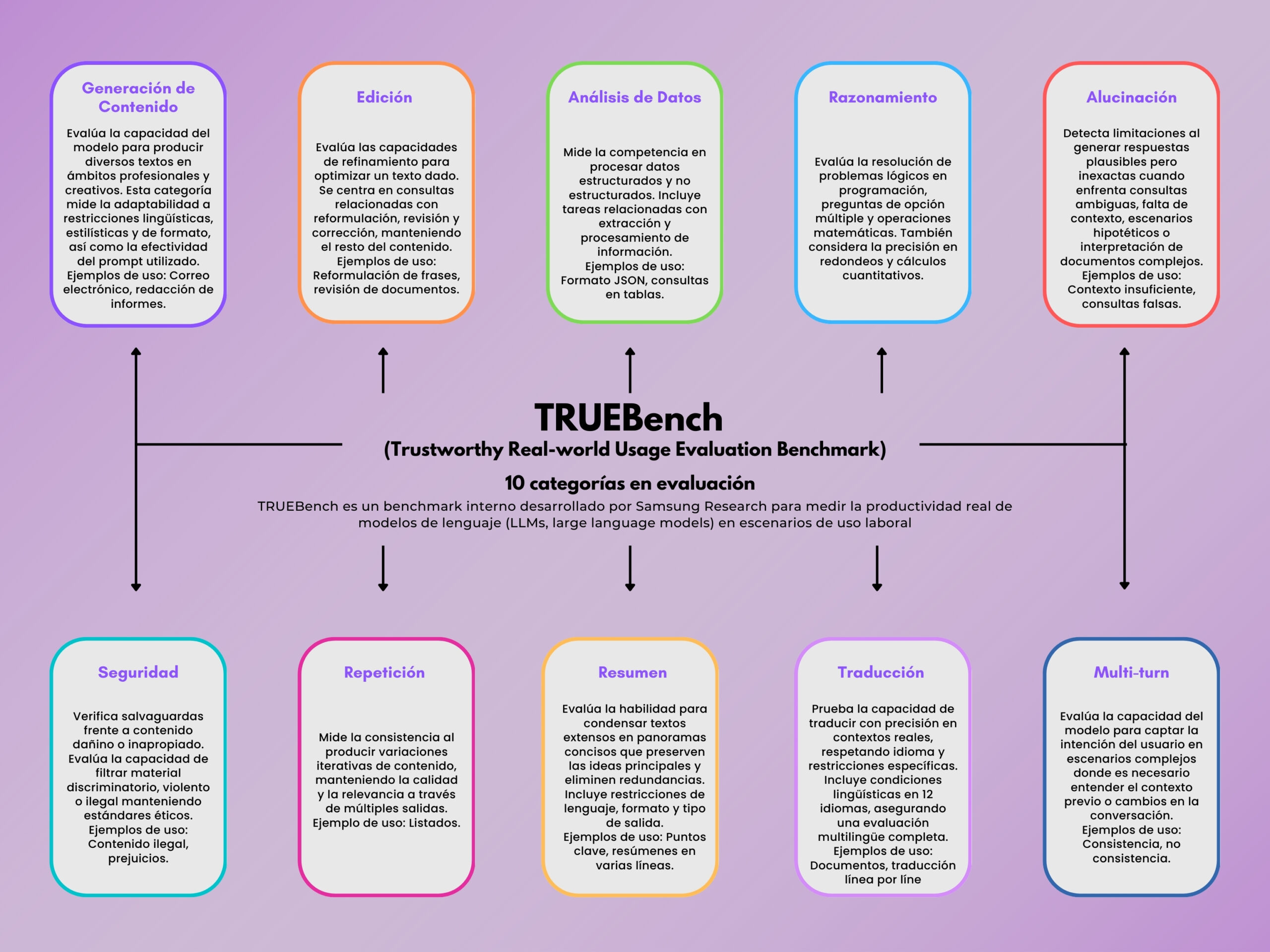
El sistema organiza su evaluación en 10 categorías con 46 subcategorías, diseñadas para cubrir un rango amplio de casos de uso:
- Generación de contenido: correos, informes, estilos de redacción.
- Edición: reescritura, corrección de estilo, mejora de textos.
- Análisis de datos: consultas SQL, JSON, tablas estructuradas.
- Razonamiento: lógica, matemáticas, preguntas de opción múltiple.
- Alucinación: detección de invención de datos en ausencia de contexto.
- Seguridad: filtrado de contenido riesgoso, ilegal o sesgado.
- Repetición: consistencia sin redundancia en múltiples respuestas.
- Resumen: reducción de textos largos a formatos más concisos.
- Traducción: soporta 12 idiomas, incluyendo escenarios multilingües.
- Multi-turn: coherencia en diálogos prolongados.
La siguiente infografía resumen las categorías publicadas por Samsung, añadiendo un ejemplo práctica de aplicación en cada caso.
El proceso de evaluación combina métricas automáticas con revisión humana. Se utiliza un ciclo iterativo de refinamiento para reducir sesgos y mejorar la objetividad de los resultados.
Resultados recientes de TRUEBench (28-09-2025)
En Hugging Face se publicó el ranking comparativo de modelos, tanto propietarios como open source. La siguiente tabla muestra la data para fines de septiembre de 2025.
Aplicabilidad técnica y alcance
TRUEBench es útil para:
- Investigadores y desarrolladores que requieren medir rendimiento en condiciones realistas.
- Empresas tecnológicas que evalúan qué modelo se ajusta mejor a flujos de trabajo específicos.
- Usuarios avanzados que experimentan con modelos open source en entornos personales y buscan métricas más prácticas que benchmarks académicos.
La incorporación de pruebas multilingües lo diferencia de la mayoría de benchmarks centrados en inglés, lo que lo vuelve más representativo en contextos globales.
Fuentes:Samsung Newsroom, Hugging Face – TRUEBench, Hugging Face – Dataset TRUEBench.
