
Desde que partió esta revolución, hemos asociado la IA con un chat, o bien como una entidad que vive dentro de una pantalla, dedicada exclusivamente a procesar datos para generar textos, código o imágenes en entornos virtuales. Sin embargo, la IA física rompe este paradigma, y se transforma en el conjunto de técnicas entre los modelos cognitivos digitales y el mundo material.
Cuando la IA tiene la capacidad para materializarse en agentes electromecánicos, hablamos de una IA física, la cual abarca desde robots industriales hasta drones y vehículos autónomos. Su gran avance radica en que permite a estas máquinas percibir su entorno espacial, razonar sobre él en milisegundos y ejecutar acciones mecánicas tangibles, pasando de ser un sistema de pura información a un agente que interactúa de manera directa con la realidad.
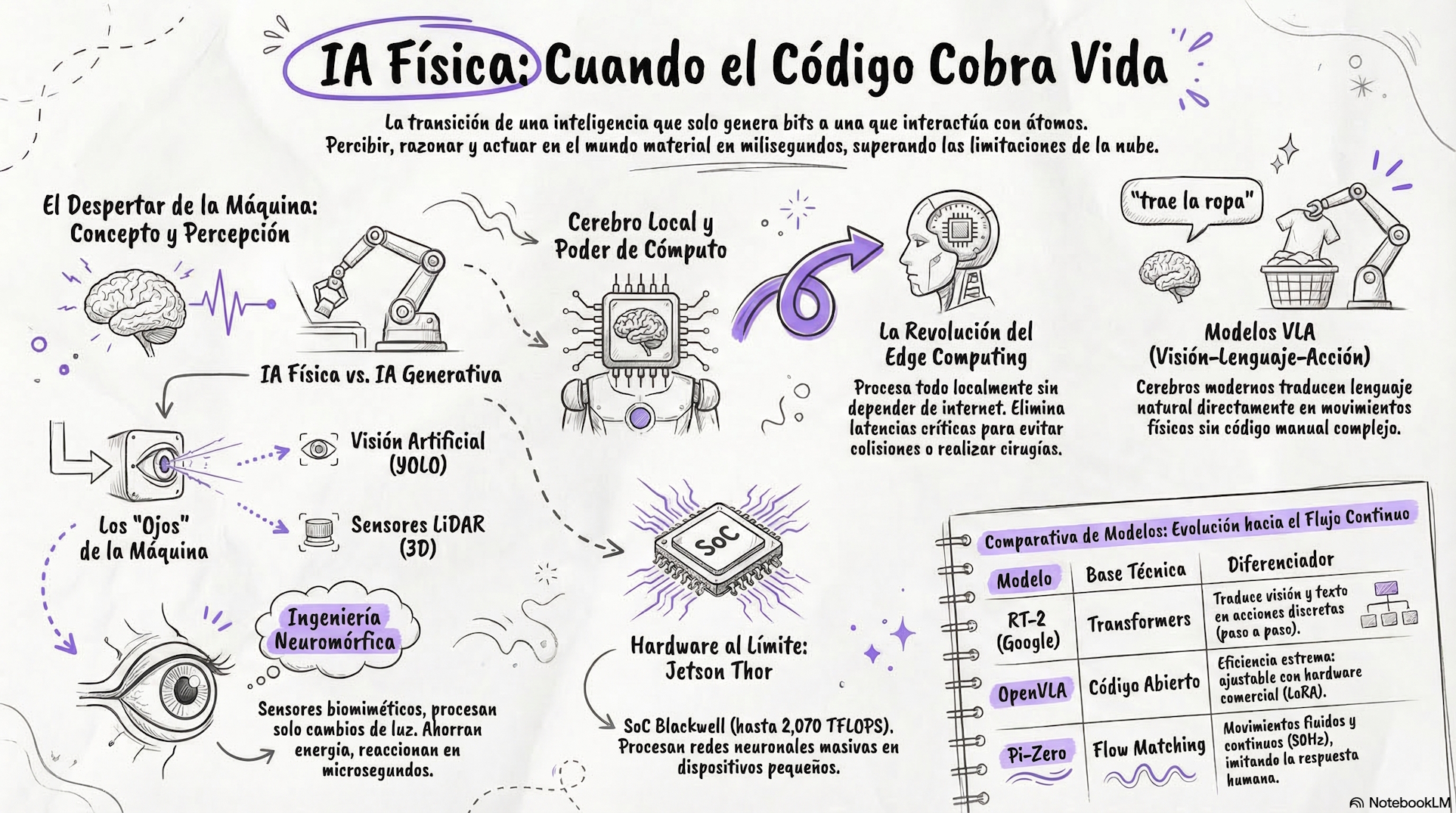
Desconectarse de internet: El edge computing
¿Qué ocurriría si un robot en pleno movimiento o un vehículo a alta velocidad debe depender de enviar terabytes de información a la nube a través de internet para saber qué hacer a continuación?.Pues este concepto lo intentan cubrir las diferentes tecnológicas creando hardware que funciona en el borde (edge), sin depender de los data centers.
Es más, si el robot o el auto transfieren datos de manera constante hacia servidores centralizados, desde luego habrá latencias de red impredecibles que resultan inaceptables cuando se trata de aplicaciones críticas para la seguridad.
Para solucionar este gran problema de cuello de botella en las telecomunicaciones, la industria ha adoptado la computación periférica, conocida universalmente como edge computing. Este enfoque traslada todo el poder de procesamiento algorítmico directamente al propio dispositivo o a nodos locales muy cercanos.
Como resultado de esta acción, al realizar el análisis de IA en el borde, se elude el tiempo de ida y vuelta de los datos, permitiendo tomar decisiones críticas al instante, proteger la privacidad de la información in situ y asegurar que el equipo siga funcionando con total normalidad, incluso si se pierde la conexión a internet.
Por este motivo, un vehículo autónomo opera en la práctica como un centro de datos móvil. Sus sistemas de percepción generan flujos masivos de información segundo a segundo, los cuales deben ser procesados directamente por el hardware integrado. Solo mediante esta ejecución in situ el sistema logra calcular maniobras de evasión y reaccionar en milisegundos ante un posible accidente, eludiendo por completo el tiempo de respuesta que exigiría comunicarse con la nube.
Hardware al límite y modelos ultracomprimidos
Dotar a un equipo móvil de la capacidad para ejecutar enormes redes neuronales de forma local exige una optimización técnica extrema. A nivel físico, esto requiere el uso de ordenadores que funcionen casi como supercomputadoras en miniatura, las cuales deben adherirse estrictamente a asfixiantes restricciones de tamaño, peso operativo y consumo de energía.
Un claro ejemplo de esto son los módulos como NVIDIA Jetson Thor, diseñados desde su concepción para satisfacer el inmenso apetito computacional de la IA física y procesar flujos masivos de sensores en tiempo real.

Por el lado del software, los modelos se comprimen hasta su máxima expresión para ser viables. Arquitecturas abiertas como OpenVLA logran adaptarse a nuevos robots y modificar sus funciones actualizando apenas un 1.4% de su matriz total de parámetros. Esta extrema eficiencia permite que inteligencias artificiales gigantescas puedan ser entrenadas y ejecutadas fluidamente, ocupando fracciones muy reducidas de memoria, logrando operar sin devorar los recursos del sistema.
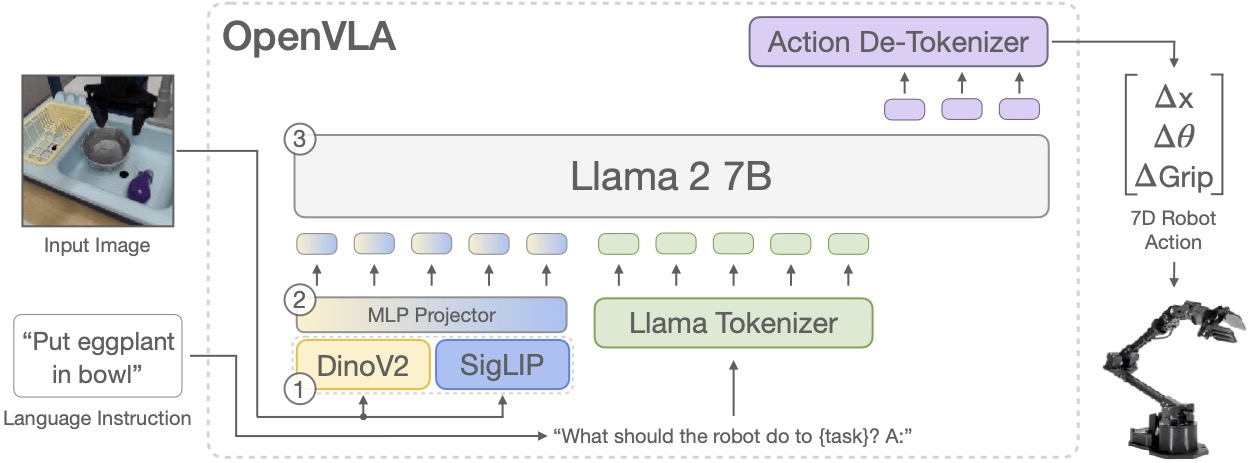
OpenVLA es un modelo de visión-lenguaje-acción (VLA) de código abierto
OpenVLA es un modelo de IA de código abierto para robots. Une visión, lenguaje y acciones en 7 mil millones de parámetros, entrenado con 970k episodios reales. Procesa imágenes, entiende instrucciones y genera movimientos precisos para manipulación generalista.
Además, supera modelos cerrados como RT-2-X (55B) en 16.5% de éxito en 29 tareas. Es eficiente, ajustable con LoRA y gratuito en GitHub/Hugging Face, impulsando robótica accesible.
Los ojos de la máquina: Modelos de visión y percepción
La percepción espacial de la IA física va más allá de la simple grabación de un video en 2D; requiere además de otros factores como:
- Compensación de deficiencias: La mezcla inteligente de estas señales permite mitigar las vulnerabilidades físicas de cada componente individual, como la escasa iluminación o los fuertes deslumbramientos solares.
- Reconstrucción continua: El sistema realiza un mapeo semántico y topológico del espacio tridimensional en estricto tiempo real.
- Fusión de sensores: Se emplea un mecanismo algorítmico vital diseñado expresamente para garantizar que el agente autónomo nunca se quede a ciegas.
- Integración de hardware: Este proceso combina de forma matemática todos los flujos de datos capturados por cámaras ópticas de alta resolución y sensores LiDAR.
Finalmente, para interpretar todo este inmenso volumen visual, entran en juego los modelos de Visión-Lenguaje-Acción (VLA). Estas arquitecturas operan bajo las siguientes características:
- Ingesta multimodal: Estas inmensas redes neuronales tienen la capacidad de procesar al mismo tiempo lo que la máquina observa espacialmente y las instrucciones de texto que recibe de los humanos.
- Traducción directa: Transforman inmediatamente toda esta información combinada en comandos de movimiento físico de bajo nivel.
- Fluidez operativa: Gracias a este procesamiento unificado, el sistema logra ejecutar tareas físicas manteniendo una gran agilidad y fluidez motriz.
- Autonomía sin código: Eluden por completo la antigua necesidad de codificar o reprogramar manualmente a la máquina para cada nueva situación o entorno que deba enfrentar.
Como ejemplo se plantea la data que pueden llegar a consumir los vehículos autónomos:
Fuentes: NVIDIA 1 / NVIDIA 2 / Globalxetfs / WEC / CSET / Deloitte / ArXiv
