
El el contexto del evento AI Infra Summit 2025, la firma estadounidense presentó la aplicación de su arquitectura NVIDIA Blackwell enfocada en las AI factories para inferencia extrema.
El concepto de NVIDIA va más allá de lo clásico de la industria del silicio, es una plataforma que combina:
- Superchips Grace Blackwell (GB200): combinan dos GPUs Blackwell con un CPU Grace mediante NVLink.
- Sistemas NVL72 a escala de rack: 72 GPUs interconectadas que operan como una única GPU lógica.
- Redes de alta velocidad: tecnologías como NVLink Switch spine, Quantum-X800 InfiniBand y Spectrum-X Ethernet para comunicación masiva entre racks.
- Software de orquestación: NVIDIA Dynamo, encargado de distribuir cargas de trabajo y optimizar recursos.
¿Qué son la inferencia extrema y las AI Factories?
La inferencia extrema es la fase en que un modelo de inteligencia artificial ya entrenado se utiliza para generar resultados a gran escala, con enormes volúmenes de datos y necesidad de máxima eficiencia.
- Requiere la mayor eficiencia energética posible para sostener cargas de este tamaño.
- Ejecuta en tiempo real modelos con cientos de miles de millones hasta billones de parámetros.
- Procesa de forma continua decenas de billones de tokens de entrada y salida por semana.
- Exige latencia muy baja, con respuestas casi instantáneas.
Para entender la idea de inferencia extrema, propongo dos analogías, la de un call center y la de un aeropuerto internacional:
Imagina un call center mundial donde millones de personas llaman al mismo tiempo con distintas consultas:
- Cada llamada debe ser atendida de inmediato, sin cortes, y usando la menor cantidad de recursos posibles.
- Esa es la exigencia de la inferencia extrema al ejecutar modelos de IA masivos.
Por otra parte, imagina un aeropuerto internacional en hora punta, con miles de vuelos que deben despegar y aterrizar de manera coordinada.
- Cualquier retraso o error afecta a todo el sistema, y además debe hacerse con el menor consumo de combustible posible.
- Así funciona la inferencia extrema al procesar billones de tokens en tiempo real.
Las AI Factories son centros de datos diseñados específicamente para ejecutar modelos de inteligencia artificial a gran escala, integrando miles de GPUs que funcionan como un único sistema.
- Están optimizadas para cargas masivas con alta eficiencia y escalabilidad.
- Operan como fábricas digitales, donde cada GPU es parte de una misma línea de producción.
- Integran miles de GPUs interconectadas como un único sistema lógico.
- Ejecutan aplicaciones de IA generativa, sistemas de recomendación y simulaciones científicas.
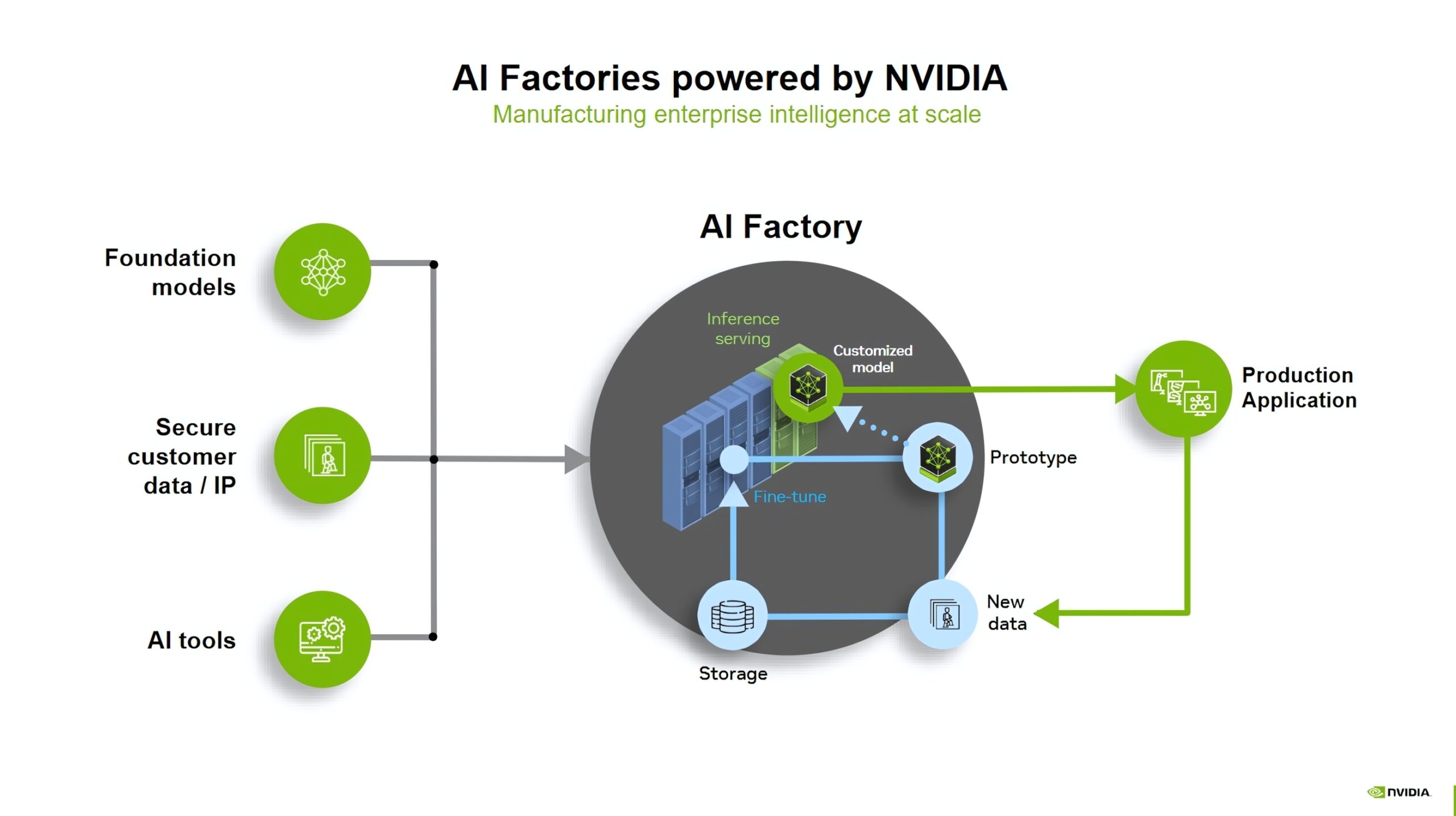
Arquitectura Grace Blackwell
El núcleo de toda la arquitectura es el superchip Grace Blackwell (GB200), que está formado por dos GPUs Blackwell y un CPU Grace, conectados mediante NVLink-C2C para operar con memoria compartida y coherente.

La configuración de este diseño reduce la latencia y optimiza el paso de datos entre CPU y GPU, lo que es clave para cargas de inferencia extrema.
El objetivo de esta arquitectura es ofrecer un sistema balanceado:
- La CPU Grace maneja grandes volúmenes de datos y la lógica de control,
- Las GPUs Blackwell ejecutan el procesamiento paralelo intensivo.
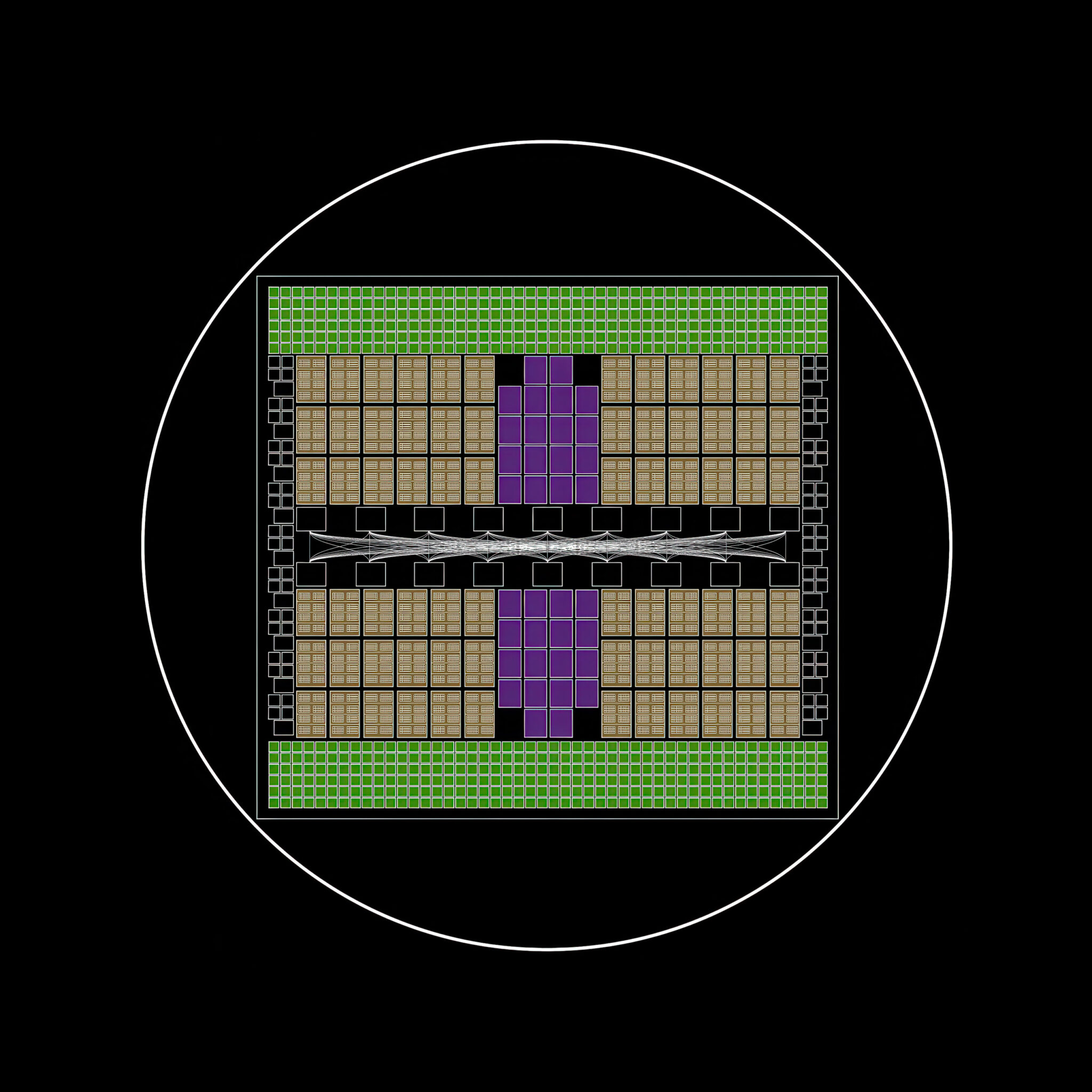
El Superchip NVIDIA GB200 Grace Blackwell
El superchip NVIDIA Grace Blackwell GB200 integra 1 CPU y 2 GPU en un único paquete para cargas de IA generativa y cómputo de alto rendimiento.
- Composición: 2 GPUs Blackwell B200 + 1 CPU Grace.
- Interconexión: NVLink-C2C con 900 GB/s de ancho de banda.
- Proceso de fabricación: 4 nm en TSMC.
- Escala de transistores: 208.000 millones por GPU.
- Potencia de cálculo: hasta 20 petaFLOPS por GPU.
- Eficiencia: 30 veces más potencia y eficiencia que H100.

Este superchip es la base del sistema NVL72, orientado a la inferencia extrema.
- Configuración NVL72: 36 CPUs Grace + 72 GPUs Blackwell.
- Conectividad: NVLink de 5ª generación.
- Refrigeración: líquida de alta densidad.
- Redes de interconexión: Spectrum-X800 y Quantum-X800 InfiniBand hasta 800 Gb/s.
- Aplicaciones: IA generativa con billones de parámetros en tiempo real.
Fabricado con el proceso de 4 nm de TSMC, cada GPU alcanza los 208.000 millones de transistores, ofreciendo hasta 20 petaFLOPS de rendimiento, lo que lo convierte en uno de los procesadores más potentes del mundo para IA generativa y cómputo de alto rendimiento.

El recorrido de fabricación comienza en las fábricas de TSMC, donde se producen obleas con decenas de chips Blackwell. Tras su verificación, los chips funcionales pasan al corte, empaquetado y montaje en módulos listos para su integración.

Los chips ensamblados se integran en una placa portadora junto a memoria de alta velocidad y componentes de gestión de energía. El resultado es un superchip preparado para escalar cargas de trabajo de IA con billones de parámetros.

¿Cómo transforma Blackwell la inferencia de IA?
La inferencia es la etapa más exigente del ciclo de vida de la IA:
- Los modelos entrenados responden a consultas en tiempo real para millones de usuarios.
- Blackwell busca optimizar este proceso combinando cómputo y comunicación de manera más eficiente.
Un gráfico publicado por NVIDIA muestra cómo la complejidad de los modelos ha crecido de manera exponencial en la última década, desde AlexNet en 2012 hasta GPT-4 y sistemas recientes que superan los billones de parámetros:
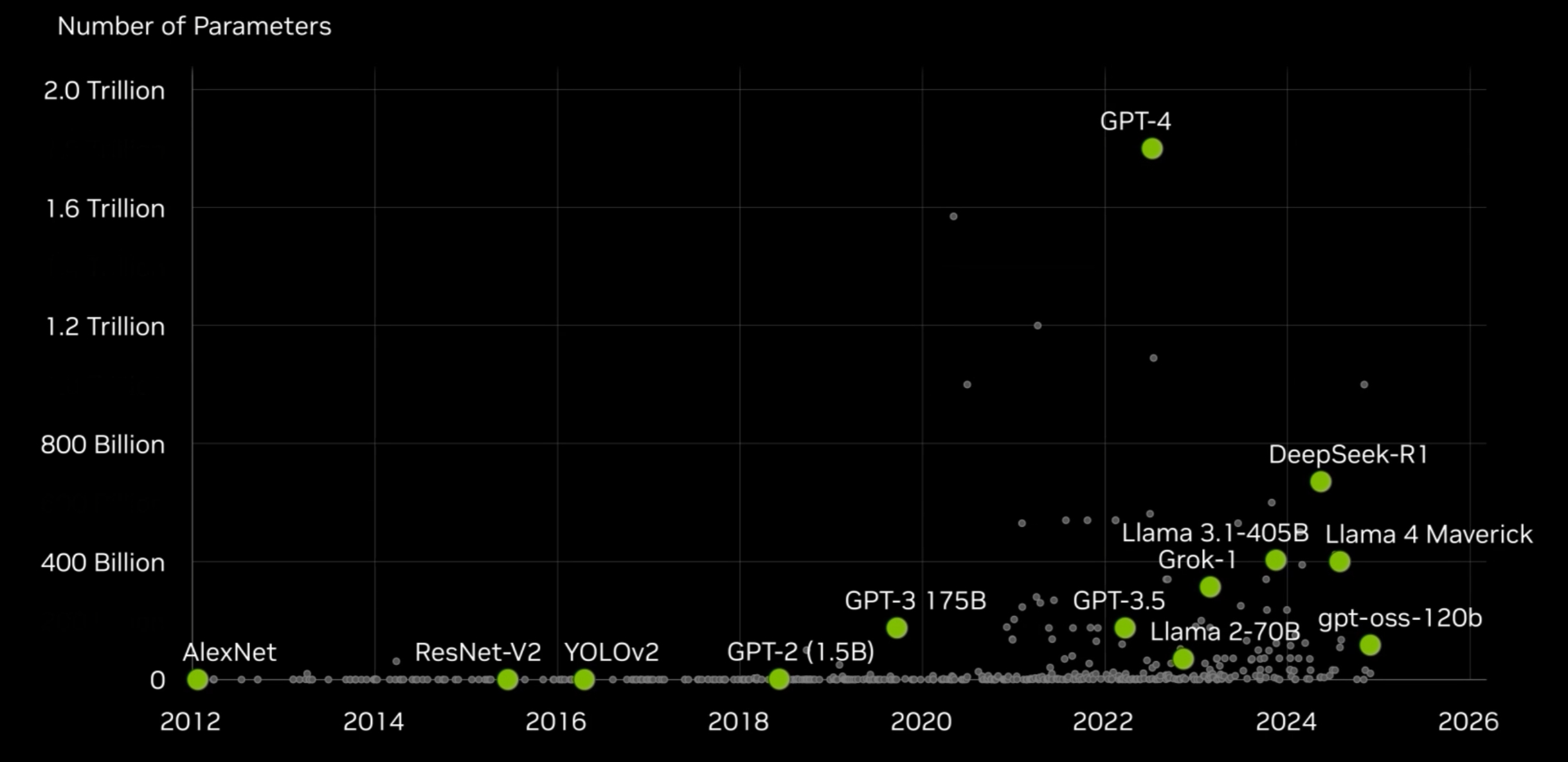
En este contexto surge el superchip Grace Blackwell (GB200), que une dos GPUs Blackwell con un CPU Grace. La interconexión NVLink permite que CPU y GPU trabajen como una unidad coherente, reduciendo la latencia y mejorando el rendimiento en cargas de inferencia.
NVL72: un rack que actúa como una sola GPU
El GB200 NVL72 es un sistema que integra 72 GPUs Blackwell en un solo rack. La interconexión mediante NVLink Switch spine entrega un ancho de banda interno de 130 TB/s, permitiendo que las GPUs operen como una sola unidad lógica.
Entre los componentes clave destacan los módulos de refrigeración, las interconexiones de cobre de alto rendimiento y los sistemas de alimentación.

Cada módulo del rack tiene dos superchips GB200, es decir, 2 CPUs Grace + 4 GPUs Blackwell.

En consecuencia, la configuración del Superchip, el módulo del rack y el rack completo queda así:
- Grace Blackwell Superchip (GB200): Integra 1 CPU Grace + 2 GPUs Blackwell unidas con NVLink-C2C.
- Módulo 1U (como los de las fotos): Contiene 2 Superchips GB200 (En total: 2 CPUs Grace + 4 GPUs Blackwell)
- Rack completo NVL72: Tiene 36 Superchips GB200 (En total: 36 CPUs Grace + 72 GPUs Blackwell funcionando como un único sistema lógico.)
Al combinar todos los módulos, el rack NVL72 funciona como una sola GPU, donde:
- Peso total: 1,5 toneladas.
- Componentes: más de 600.000 piezas ensambladas.
- Cableado interno: más de 3 kilómetros de interconexiones de alta velocidad.
- Software: millones de líneas de código que permiten operar el sistema como una sola GPU virtual.
- Escala global de fabricación: más de 1,2 millones de subcomponentes producidos en 150 instalaciones y ensamblados en colaboración con 200 socios tecnológicos.


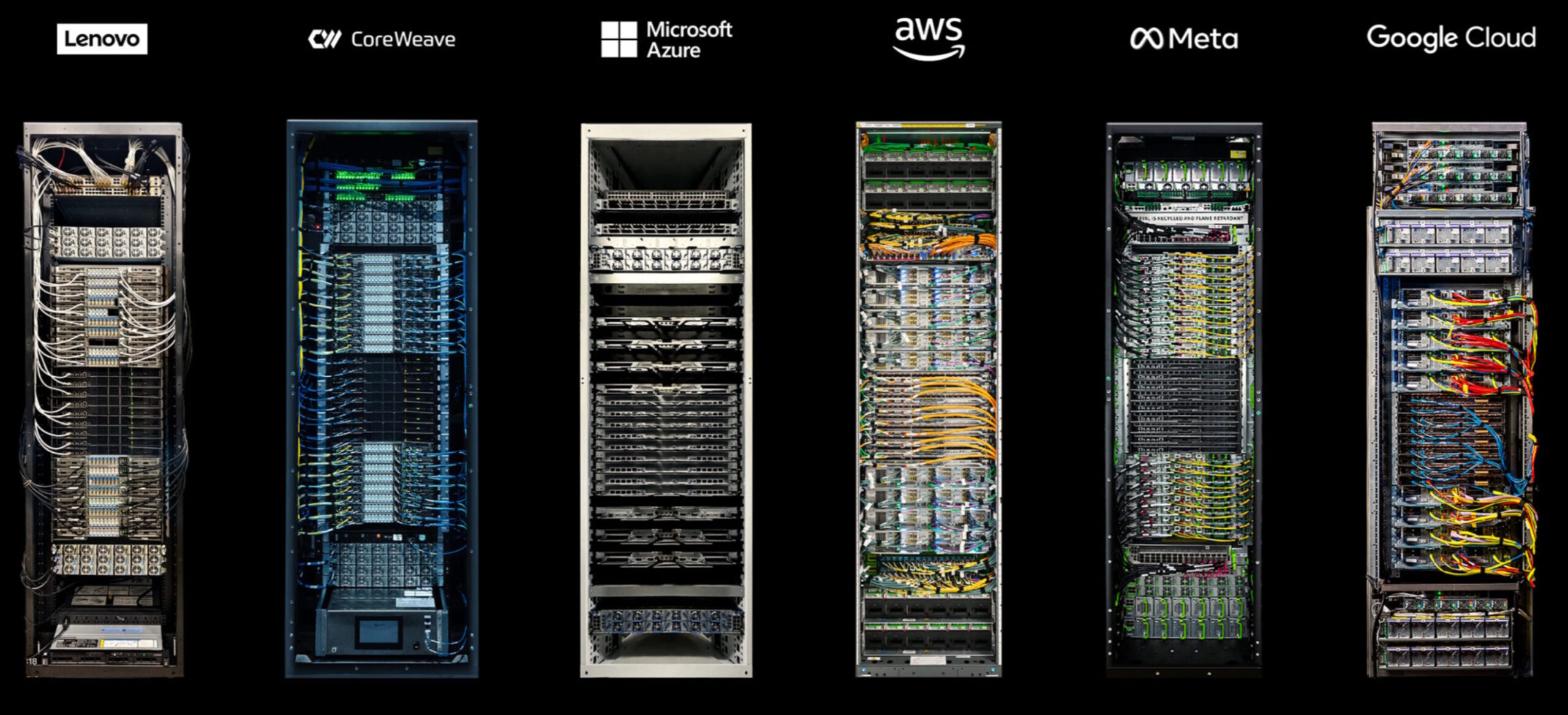
La siguiente galería muestra cómo los partners de NVIDIA usan la modularidad que proporciona Blackwell para sus propios racks:


Redes para AI Factories
El diseño de Blackwell está orientado a escalar más allá de del propio rack. Con Quantum-X800 InfiniBand y Spectrum-X Ethernet, es posible conectar varios racks NVL72 en una infraestructura coordinada. Estas instalaciones conforman las AI Factories, centros de datos optimizados para cargas de inferencia masiva y entrenamiento de modelos generativos.
La siguiente imagen muestra cómo son los componentes internos de los módulos de conectividad:

Quantum-X800 InfiniBand Switch: provee una red de interconexión con baja latencia y hasta 800 Gbps por puerto, diseñada para cargas HPC y entrenamiento/inferencia de IA a gran escala. Permite comunicación determinística y pérdida cero en clústeres de decenas de miles de nodos.
NVLink Switch: ofrece comunicación directa entre GPUs con coherencia de memoria, sin necesidad de pasar por la CPU. En el NVL72, conecta 36 GB200 Superchips (72 GPUs) en una topología de malla, actuando como la columna vertebral interna de las AI factories
Spectrum-X Ethernet Switch: solución Ethernet optimizada para IA generativa y cargas de inferencia masiva. Incorpora telemetría avanzada, aislamiento de tráfico y soporte para hasta 400 Gbps por conexión, integrándose con las NICs ConnectX-7 para escalar centros de datos sobre infraestructura Ethernet existente.
NVIDIA Dynamo: el sistema operativo de las AI Factories
La operación de una AI Factory no depende solo del hardware, requiere de software que todo, para esto, NVIDIA presentó Dynamo, que actuaría como el sistema operativo de las granjas de IA.
¿Qué puede hacer Dynamo?
- Orquestación de inferencia: distribuye y coordina peticiones en grandes flotas de GPUs.
- Optimización de costos: busca que la operación de la AI Factory se ejecute al menor costo posible.
- Escalabilidad dinámica: agrega o retira GPUs de las cargas según la demanda en tiempo real.
- Balanceo de carga: redirige consultas hacia los procesadores más adecuados para cada tarea.
- Máxima utilización de recursos: evita que GPUs queden inactivas y asegura que todo el hardware trabaje al máximo rendimiento posible.

¿Qué te parecen las novedades de NVIDIA en materia de las AI Factories para inferencia extrema?
Fuente: NVIDIA
