NVIDIA informó que su plataforma Blackwell NVL72 registró los menores tiempos de entrenamiento en las siete pruebas de MLPerf Training 6.0. La evaluación incluyó cargas nuevas con modelos mixture-of-experts, entrenamiento distribuido en miles de GPU y comparaciones entre sistemas GB200 NVL72 y GB300 NVL72.
NVIDIA Blackwell NVL72 cubrió todas las pruebas de MLPerf Training 6.0
La edición 6.0 de MLPerf Training incorporó pruebas con DeepSeek-V3 671B y GPT-OSS 20B, dos modelos de arquitectura mixture-of-experts. En estos sistemas, solo una parte del modelo se activa para procesar cada entrada, por lo que el entrenamiento depende tanto de la potencia de cálculo como de la comunicación entre GPU.
NVIDIA señala que Blackwell NVL72 conecta 72 GPU dentro de un rack mediante NVLink de quinta generación. Esa configuración permite trabajar con un conjunto compartido de cómputo y memoria, una condición relevante cuando miles de procesos deben coordinarse durante el entrenamiento.
Los tiempos informados para Blackwell NVL72 fueron los siguientes:
- DeepSeek-V3 671B: 2,02 minutos.
- GPT-OSS 20B: 7,43 minutos.
- Llama 3.1 405B: 7,07 minutos.
- Llama 2 70B LoRA: 0,40 minutos.
- Llama 3.1 8B: 4,46 minutos.
- FLUX.1: 17,1 minutos.
- DLRM-dcnv2: 0,67 minutos.
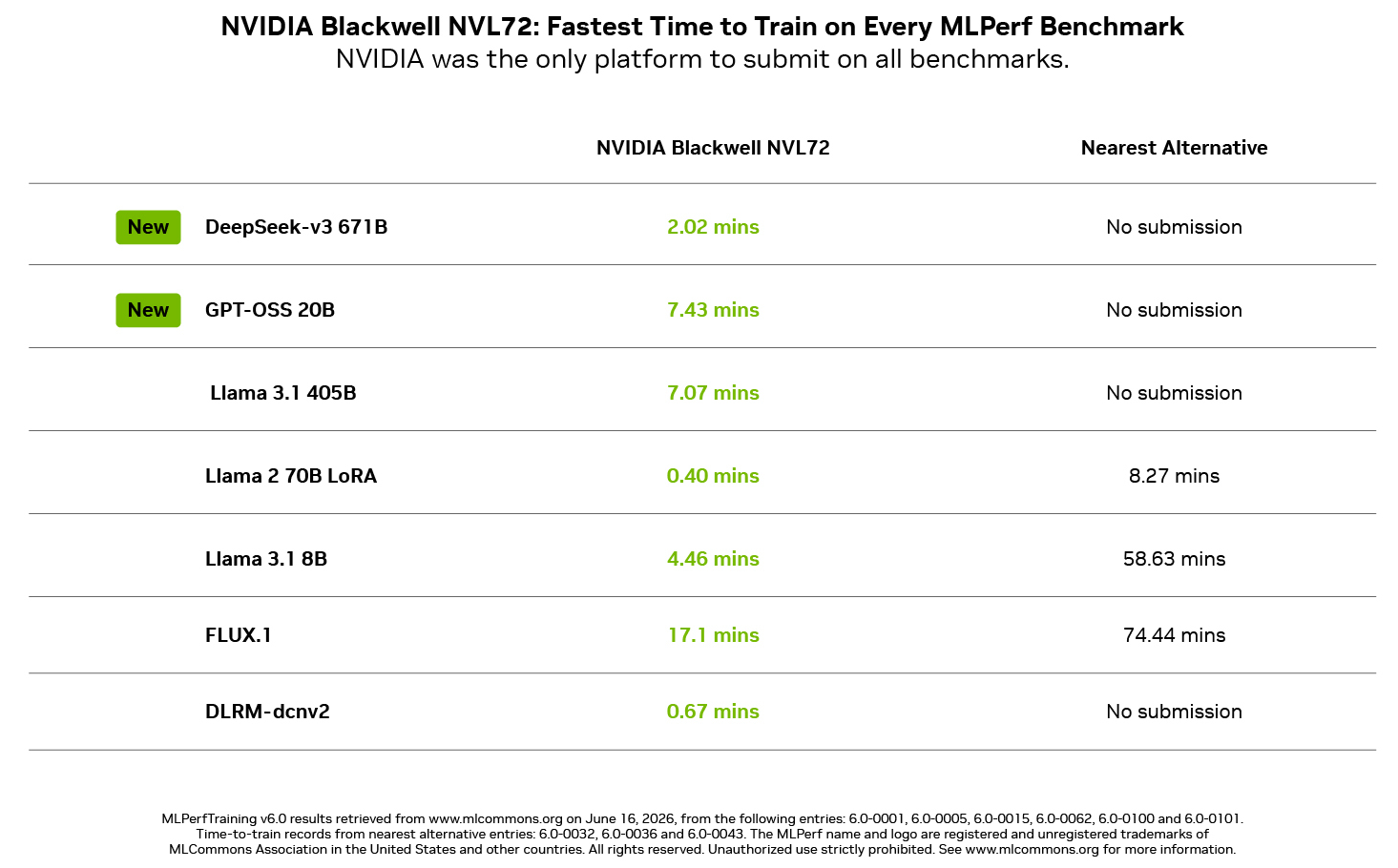
En la tabla de NVIDIA, solo tres de las siete pruebas muestran un tiempo para otra plataforma. En esos casos, la comparación queda así:
- FLUX.1: de 74,44 minutos a 17,1 minutos.
- Llama 2 70B LoRA: de 8,27 minutos en la alternativa a 0,40 minutos en Blackwell NVL72.
- Llama 3.1 8B: de 58,63 minutos a 4,46 minutos.
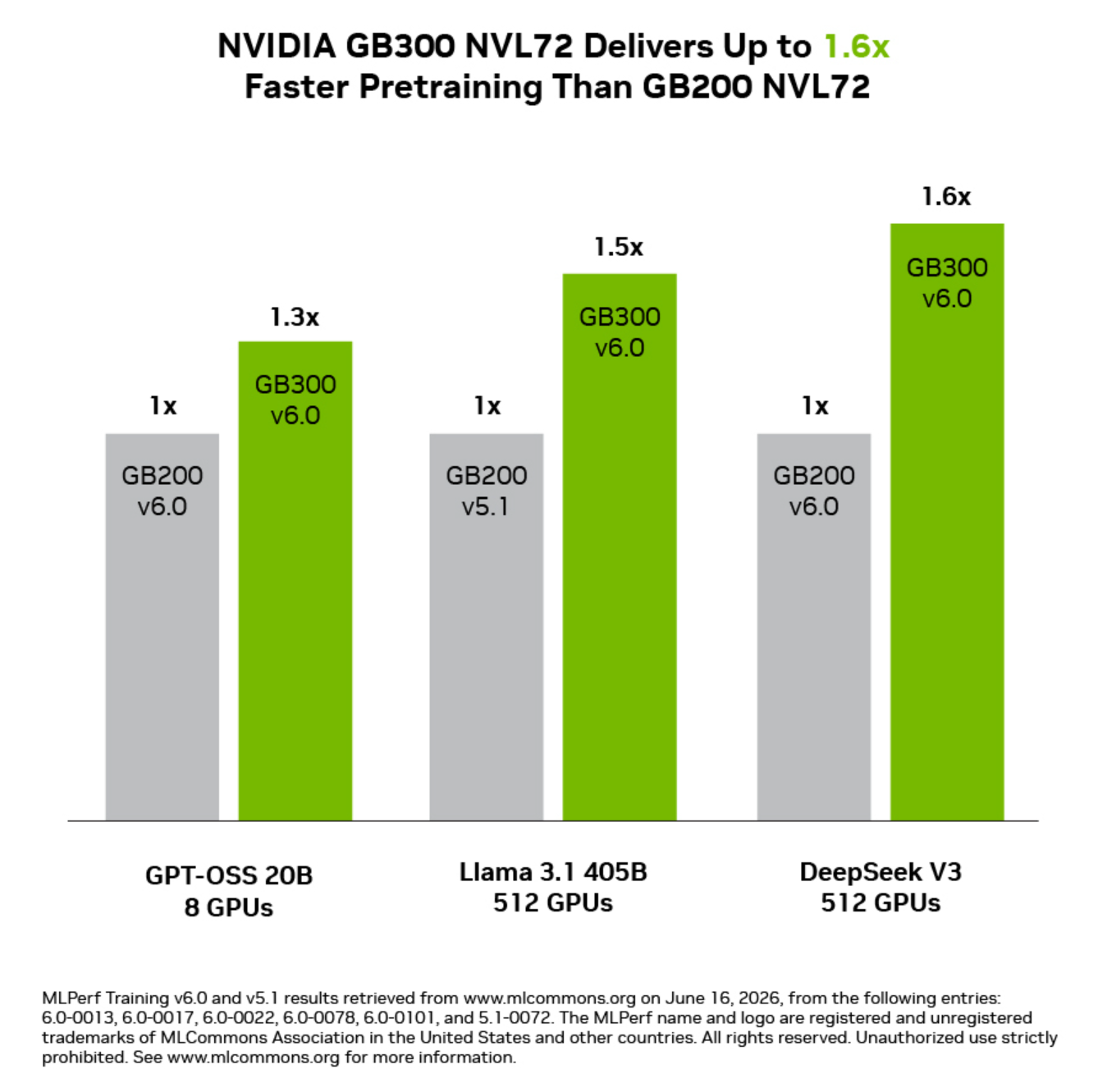
GB300 NVL72 mejora frente a GB200 NVL72
NVIDIA comparó GB300 NVL72 con GB200 NVL72 en cargas de preentrenamiento; en los datos publicados por la firma, GB300 NVL72 fue hasta 1,6 veces más rápido, con diferencias asociadas a mayor densidad de cómputo, más capacidad de memoria y un límite de potencia superior.
Las mejoras mostradas por NVIDIA fueron las siguientes:
- GPT-OSS 20B con 8 GPU: 1,3 veces frente a GB200 v6.0.
- Llama 3.1 405B con 512 GPU: 1,5 veces frente a GB200 v5.1.
- DeepSeek V3 con 512 GPU: 1,6 veces frente a GB200 v6.0.
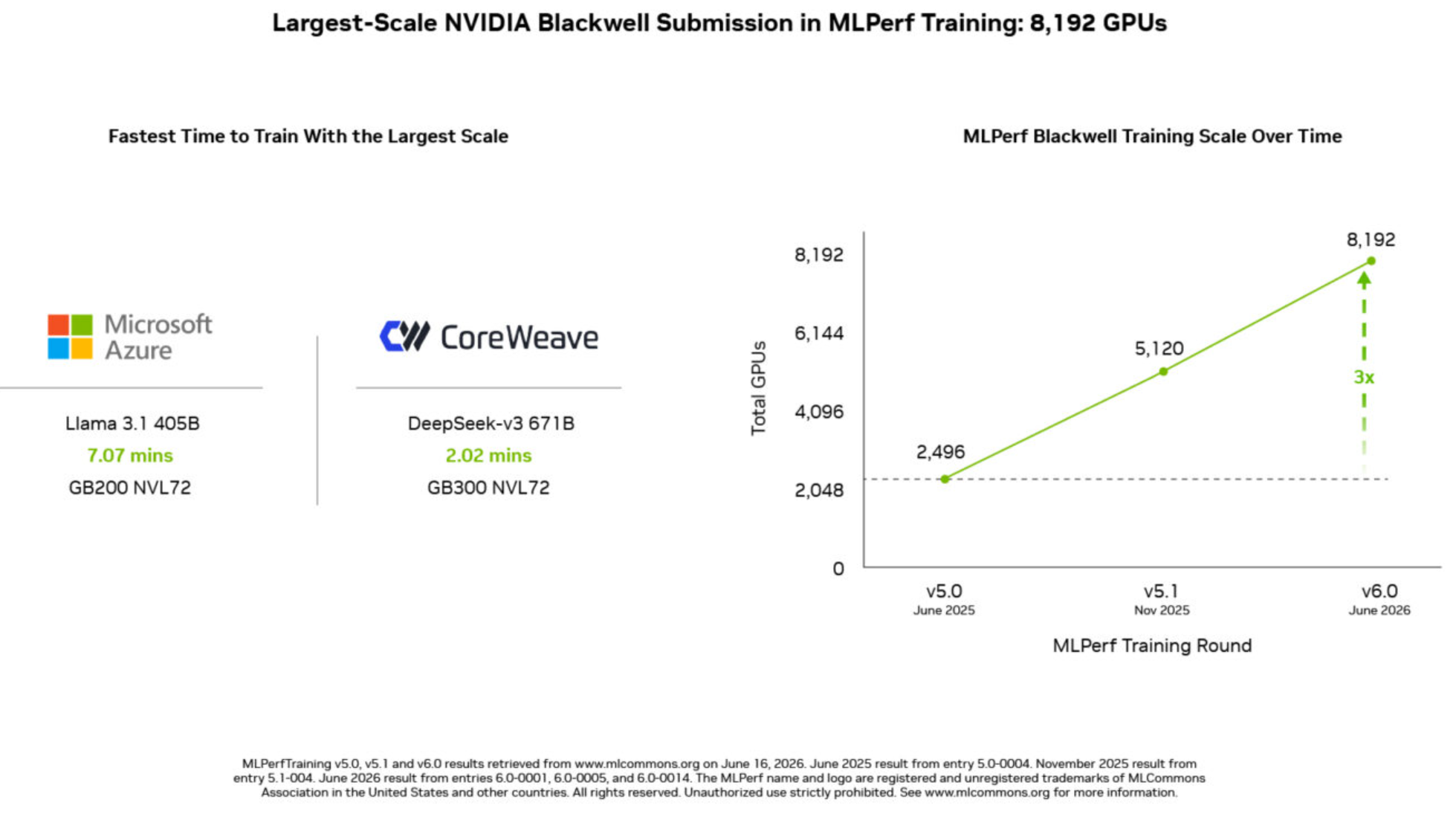
Blackwell escala hasta 8.192 GPU en MLPerf Training 6.0
Los resultados publicados por NVIDIA muestran un aumento sostenido en la escala de Blackwell dentro de MLPerf Training, con envíos que pasaron de 2.496 GPU en junio de 2025 a 5.120 GPU en noviembre del mismo año y a 8.192 GPU en junio de 2026.
Los resultados a mayor escala que se muestran en la imagen fueron los siguientes:
- Microsoft Azure: Llama 3.1 405B en 7,07 minutos con GB200 NVL72.
- CoreWeave: DeepSeek-V3 671B en 2,02 minutos con GB300 NVL72.
- Escala máxima mostrada: 8.192 GPU en MLPerf Training 6.0.