OpenAI presentó recientemente dos versiones reducidas de Chat GPT-5.4. Se trata de mini y nano, dos variantes orientadas a cargas de trabajo de alto volumen donde la latencia y el costo operativo son factores relevantes.
Frente al modelo de mayor tamaño, la compañía posiciona estas versiones como alternativas más rápidas y eficientes en temas de programación, subagentes y tareas de apoyo. Es decir, la versión mini apunta a conservar un rendimiento alto en más escenarios, mientras nano se enfoca en velocidad y costo en trabajos más acotados.
Rendimiento técnico frente a versiones anteriores
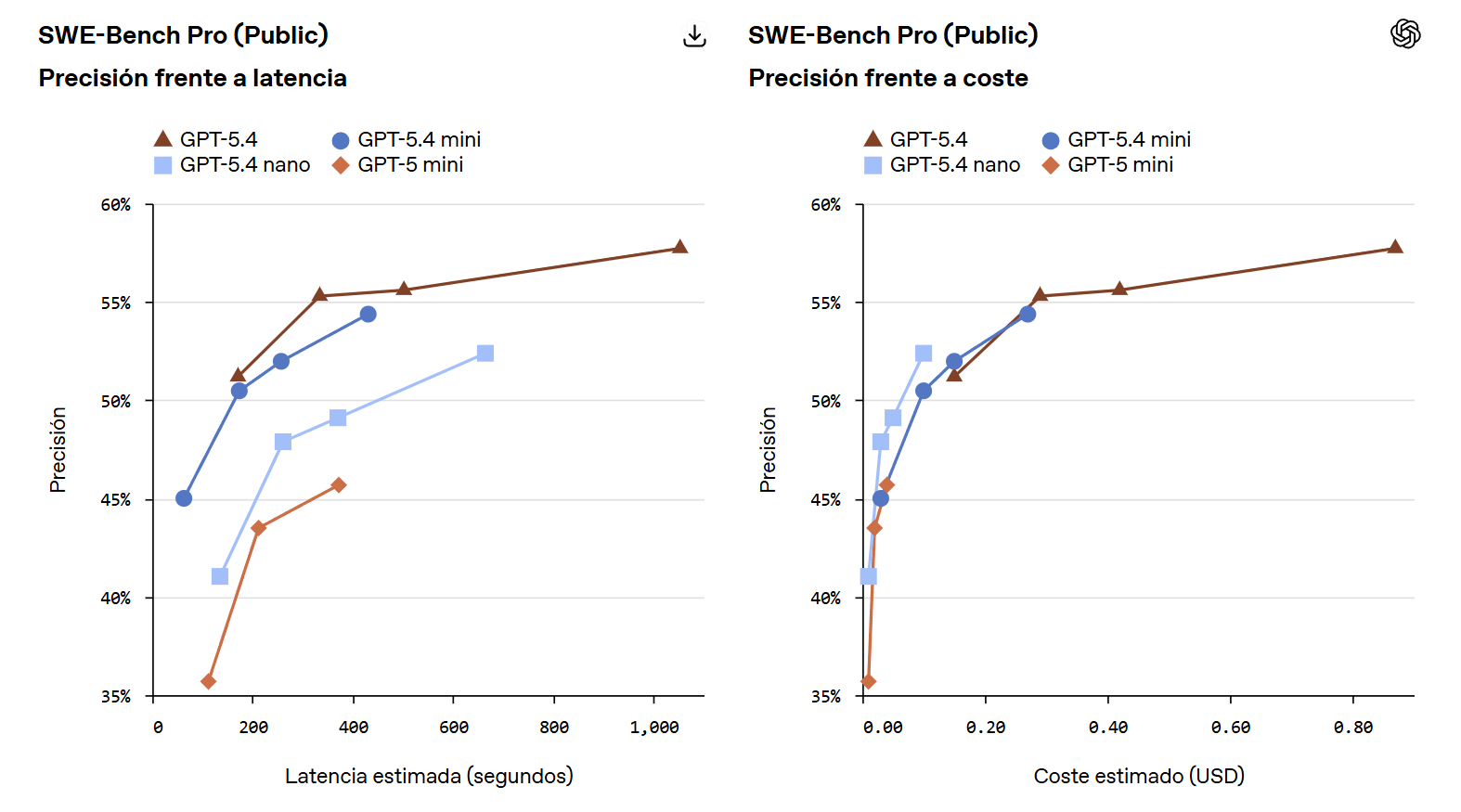
Los resultados publicados por OpenAI en las distintas pruebas demuestran un equilibrio notable entre eficacia y consumo de recursos computacionales. En la evaluación específica SWE-Bench Pro, la versión mini alcanzó un 54.4% de precisión. Esta cifra supera de manera clara el 45.7% registrado por la generación previa correspondiente a GPT-5 mini.
Por su parte, el modelo nano también presenta métricas sólidas al registrar un 52.4% de efectividad en la misma prueba pública. Su diseño prioriza la reducción del esfuerzo computacional, logrando posicionarse como una alternativa viable para tareas de programación ágil donde la velocidad es crítica.
Adicionalmente, las evaluaciones en áreas de conocimientos generales muestran resultados competitivos. En la prueba GPQA Diamond, la edición mini obtuvo un 88.0% de respuestas correctas, mientras que la variante nano consiguió un 82.8%.

Evaluación en sistemas operativos y herramientas
En entornos de prueba orientados a comandos, como Terminal-Bench 2.0, el modelo GPT-5.4 mini logra un 60.0% de rendimiento, superando con creces el 38.2% de la versión anterior. Por su parte, la variante nano alcanza un 46.3%, demostrando su utilidad en operaciones de terminal a pesar de su arquitectura reducida.
Respecto al uso de herramientas, la métrica Toolathlon ubica a la versión mini con un 42.9% de precisión y a la nano con un 35.5%. En este apartado, ambas opciones compactas mantienen una ventaja sobre el 26.9% obtenido por GPT-5 mini.
Sin embargo, en tareas de mayor complejidad técnica medidas por OSWorld-Verified, el modelo mini sostiene un alto nivel con un 72.1% y se acerca al desempeño de GPT-5.4. En cambio, la versión nano registra un 39.0%, lo que muestra un recorte más evidente en este tipo de interacción con el sistema operativo.
Eficiencia en latencia y reducción de costos operativos
Según las estimaciones presentadas por OpenAI, los modelos compactos se ubican con menor latencia y menor costo estimado que GPT-5.4, especialmente en flujos de programación y tareas de apoyo donde importa responder con rapidez.
Esta relación entre costo, velocidad y capacidad permite a los equipos de desarrollo ejecutar múltiples procesos a gran escala, manteniendo los presupuestos controlados y un nivel de rendimiento competitivo en tareas específicas.