
Fujitsu fue seleccionada por RIKEN para diseñar la supercomputadora FugakuNEXT, que sucederá a Fugaku, se espera que la actualización mantenga a Japón en la punta de lanza, en marteria de compúto para la ciencia.
De acuerdo con DCD, el contrato firmado contempla la fase de diseño básico, extendiéndose hasta febrero de 2026, con la expectativa de definir la arquitectura global del sistema y los componentes de cómputo.
FugakuNEXT: Proyecto, Alcance y nuevos procesadores
La hoja de ruta del supercómputo japonés entra en una nueva fase con la selección oficial de Fujitsu para el desarrollo de FugakuNEXT. Estos son los principales puntos que definen el proyecto y su alcance inicial:
- Fujitsu ha sido seleccionada para diseñar el sucesor del superordenador Fugaku, denominado FugakuNEXT.
- El contrato está alojado en el instituto japonés Riken y cubre la totalidad del hardware informático, con una fase de diseño básico hasta febrero de 2026.
- El objetivo institucional es que FugakuNEXT permita heredar y potenciar las aplicaciones ya existentes en Fugaku, además de incorporar capacidades avanzadas en inteligencia artificial.
- El Ministerio japonés MEXT planteó en 2024 la creación de FugakuNEXT con la meta de desarrollar la primera supercomputadora a escala zetta del mundo.
- El rendimiento zetta previsto se centrará en aplicaciones de inteligencia artificial (FP8), diferenciándose del estándar tradicional de cálculo de doble precisión (FP64) para supercomputadoras.
- Cada nodo de FugakuNEXT podría superar “varios cientos” de teraflops FP64, acercándose a un rendimiento total en el rango de los hexaflops.
- Fugaku, implementado en 2020 y basado en arquitectura Arm, alcanzó 442,01 petaflops, liderando el ranking Top500 de ese año y situándose actualmente en el séptimo lugar a nivel mundial.
Nuevos procesadores Fujitsu-MONAKA y MONAKA-X
El desarrollo de FugakuNEXT está respaldado por una nueva generación de procesadores, resultado de la estrategia de innovación de Fujitsu en computación de alto rendimiento. A continuación, se presentan los aspectos clave de las familias Fujitsu-MONAKA y MONAKA-X:
- Fujitsu está desarrollando CPUs bajo el nombre código Fujitsu-MONAKA, con lanzamiento previsto para 2027 y orientadas a la eficiencia energética.
- Los chips MONAKA emplean tecnología de 2 nanómetros, integran GPU y aceleradores, y están diseñados para empaquetado 3D avanzado y operación de voltaje muy bajo.
- La arquitectura de FugakuNEXT combinará CPU Arm con GPU Instinct de AMD, según el anuncio realizado por Fujitsu.
- Fujitsu-MONAKA-X, denominadas provisionalmente, serán las sucesoras de los procesadores MONAKA y constituirán la base de FugakuNEXT.
- Estos nuevos procesadores buscarán no solo potenciar las aplicaciones científicas, sino también responder a las demandas de aceleración de IA a gran escala.
- Fujitsu aspira a canalizar la experiencia adquirida en el desarrollo de MONAKA y MONAKA-X hacia futuras Unidades de Procesamiento Neuronal (NPU) y procesadores de IA avanzados para diferentes industrias y la sociedad en general.
Análisis del Desarrollo de CPUs Fujitsu-MONAKA para FugakuNEXT
¿Qué avances técnicos introduce FugakuNEXT respecto a su antecesor?
FugakuNEXT introduce una arquitectura heterogénea, con procesadores ARMv9 Monaka-X de aproximadamente 144 a 150 núcleos por CPU, diseñados para operar junto a aceleradores como GPUs de alto rendimiento.
La arquitectura está pensada para ejecutar cargas mixtas de simulación científica e inteligencia artificial, facilitando la convergencia entre ambas disciplinas en una sola plataforma.
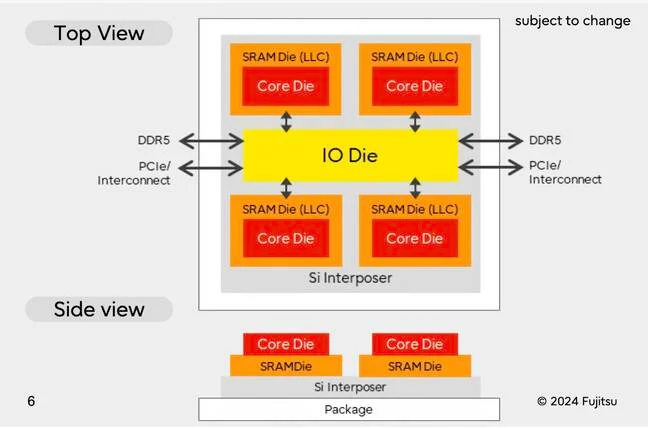
El diseño de la CPU Fujitsu-MONAKA se configura como un chiplet avanzado, en la que los núcleos Armv9 y los módulos de caché SRAM se distribuyen en matrices separadas (ver imagen). Ambos componentes se conectan mediante un IO Die (Input/Output Die, o “dado de entrada/salida”) central sobre un interposer de silicio (capa intermedia de silicio).
Nota editorial: Un IO Die (Input/Output Die, o “dado de entrada/salida”) es un chip especializado dentro de una arquitectura chiplet cuyo propósito es centralizar y gestionar todas las funciones de entrada y salida de datos del procesador.
En el artículo de The Register, se señala que la arquitectura es comparable a la usada en las CPUs AMD Epyc-X con caché apilada, permite aumentar la densidad de núcleos y optimizar el rendimiento por vatio en entornos de alto rendimiento. A continuación se muestra el esquema preliminar divulgado por Fujitsu.
¿Cómo se gestionarán la memoria y el almacenamiento en FugakuNEXT?
La configuración considera memoria DDR5 en las CPUs y HBM de nueva generación en los aceleradores. Con esta configuración se pueden alcanzar anchos de banda combinados de lectura y escritura (en total por nodo), que podrían sumar varios cientos de terabytes por segundo.
Por su parte, en el artículo de Toms Hardware, señala que se estima el uso de almacenamiento jerárquico combinando tecnologías NVMe y NVRAM por nodo. Además, el sistema integrará un archivo paralelo centralizado cuya capacidad total superará los 150 petabytes.
El sistema utilizará una nueva generación de red de interconexión, basada en la tecnología Tofu (usada inicialmente en Fugaku) , para unir todos los nodos de cómputo. Esto permitirá transmitir datos entre los procesadores y los aceleradores de forma casi instantánea.
Según el documento técnico de Fujitsu, Tofu se define como:
[…] Una arquitectura de interconexión desarrollada para supercomputadoras como Fugaku, basada en una red de malla/toroide de seis dimensiones que permite la comunicación de alta velocidad y baja latencia entre decenas de miles de nodos.
Fujitsu Limited. (2020). The Tofu Interconnect D for Supercomputer Fugaku [PDF].
FugakuNEXT integrará enlaces de última generación con soporte para PCIe 6.0 y CXL 3.0, lo que permite una comunicación eficiente tanto entre nodos de cómputo como entre procesadores y aceleradores.
En términos de eficiencia energética, las CPUs Monaka-X implementan circuitos optimizados para operar con muy bajo voltaje y aprovechan el empaquetado chiplet 3D. El sistema está diseñado para lograr una mejora significativa en rendimiento por vatio respecto a Fugaku, manteniendo o reduciendo el consumo eléctrico total mediante refrigeración avanzada y gestión de la temperatura por rack de servidores.

¿Cuál es la meta de rendimiento y por qué se definen esas precisiones de número?
Japón apunta a lo mejor, el Centro RIKEN para la Ciencia Computacional (R‑CCS), espera multiplicar la capacidad de cómputo de Fugaku entre 5 y 10 veces en simulaciones científicas.
El objetivo del sistema es conseguir un desempeño a nivel de exaescala (10¹⁸) en FP64 y a superar el zetaescala (10²¹) en inteligencia artificial, alcanzando más de 10²¹ operaciones por segundo en formatos FP8 o INT8 para IA.
El sistema apunta a un desempeño exaescala en FP64 y a superar el zettascale en inteligencia artificial, alcanzando más de 10²¹ operaciones por segundo en formatos FP8 o INT8 para IA, es decir:
- Exaescala en FP64: significa que podrá realizar al menos un trillón de operaciones matemáticas complejas por segundo usando cálculos de doble precisión, que son los más exigentes y precisos en ciencia y simulación.
- Zetaescala en inteligencia artificial, es decir, procesar más de 10²¹ operaciones por segundo, pero utilizando formatos de menor precisión como FP8 o INT8, que se emplean en modelos de IA para lograr un mayor volumen de cálculos en menos tiempo.
¿Por qué se usa FP8 en IA y FP64 en simulaciones científicas como formatos de precisión numérica o precisión de coma flotante?
En la etapa de entrenamiento e inferencia de modelos de IA, se espera procesar la mayor cantidad de datos en el menor tiempo y menor consumo energético. Por su parte, en simulaciones científicas se busca el alta precisión.
FP8 en IA:
- Permite procesar más operaciones por segundo, usando menos memoria y energía.
- Es suficiente para el entrenamiento y la inferencia de modelos de redes neuronales, que no requieren máxima exactitud en los cálculos.
- Optimiza el hardware, acelera los tiempos de entrenamiento y permite el uso de modelos más grandes.
FP64 en simulaciones científicas:
- Proporciona alta exactitud y reduce el riesgo de errores numéricos acumulativos.
- Es necesario en simulaciones complejas (clima, física, química, dinámica de fluidos) donde la precisión es crítica para la validez de los resultados.
- Garantiza que los cálculos científicos sean fiables y reproducibles.
¿Cómo posiciona FugakuNEXT a Japón en la supercomputación y la IA científica?
Cada nodo de FugakuNEXT podrá alcanzar decenas de petaflops por segundo en cálculos de precisión media o baja, como FP16, FP8 o INT8. Esta capacidad permitirá llevar a cabo tareas avanzadas en materia de IA y aprendizaje profundo a gran escala.
El sistema está concebido como una plataforma convergente, es decir, una infraestructura capaz de integrar diferentes tipos de cómputo, como:
- Simulación científica.
- Inteligencia artificial.
- Potencialmente, computación cuántica.
En la práctica, estos recursos pueden operar de forma aislada o en conjunto y en paralelo, potenciando la investigación y la resolución de problemas complejos. Con esto en mente, Japón busca consolidar una base estratégica que aporte beneficios en distintos ámbitos, entre los que destacan:
- Análisis avanzado para “AI for Science”
- Entrenamiento de modelos de IA de última generación
- Procesamiento masivo de datos
- Optimización de algoritmos de aprendizaje profundo
¿Iremos a ver este nivel de compromiso con la ciencia en Chile?
Fuentes: 1 / 2 / 3 / 4 / 5 / 6 / 7 / 8
