
En el marco de la conferencia ICML 2025 (International Conference on Machine Learning, realizada del 13 al 19 de julio en Vancouver, Intel Labs y el Instituto Weizmann de Ciencia presentaron una mejora en la técnica de decodificación especulativa, en su estudio titulado «Speculative Decoding is All You Need for Fast LLM Inference«, centrado en una técnica de aceleración para modelos de lenguaje grandes (LLM).
La propuesta de ambos laboratorios, radica en el hecho de que esta técnica usa un modelo pequeño como borrador para generar tokens anticipados, que luego valida un modelo de lengua de gran tamaño (LLM), reduciendo significativamente el tiempo de inferencia (una predicción).
¿Qué es la decodificación especulativa y por qué aporta al avance?
La decodificación especulativa es una técnica de optimización cuyo objetivo es acelerar las predicciones en los modelos de lenguaje grande, en palabras de Google Research:
«La decodificación especulativa es la aplicación del muestreo especulativo a la inferencia de modelos autorregresivos, como los transformadores. Utiliza un modelo auxiliar para proponer múltiples tokens en paralelo, y luego un modelo verificador más potente para aprobar o rechazar esas propuestas, lo que permite acelerar la inferencia manteniendo la misma distribución de salida».
En el siguiente video desarrollado por Google Research muestra una comparación visual del rendimiento de un modelo de lenguaje con y sin decodificación especulativa, aplicada en el contexto de Google Search con IA generativa:
En este segundo video se muestra visualmente la diferencia entre el método tradicional de generación de texto y el enfoque con decodificación especulativa.
¿Qué diferencia al enfoque de Intel y Weizmann del resto?
El estudio presentado por Intel Labs y el Instituto Weizmann en ICML 2025 representa un avance sustantivo en IA, no está solo en aplicar la decodificación especulativa, sino en superar las limitaciones técnicas de trabajos anteriores, como el planteado por Google Research en 2023.
En su propuesta original, Google demostró que era posible usar un modelo pequeño para anticipar tokens que luego validaría un modelo grande (LLM), acelerando la inferencia. Sin embargo, esta técnica dependía de que ambos modelos compartieran vocabulario y hubieran sido entrenados de forma conjunta.
El aporte central de Intel y Weizmann cambia el enfoque hacia modelos independientes que logran:
- Permiten que el modelo auxiliar y el modelo principal sean completamente distintos
- El modelo pequeño o auxiliar puede ser de un proveedor diferente al LLM
- La decodificación especulativa se vuelve una técnica universal, interoperable y abierta.
- Apta para escenarios reales donde conviven modelos de múltiples orígenes.
Oren Pereg, investigador senior en Intel Labs, afirmó:
“Hemos resuelto una ineficiencia central en la IA generativa… ya se está usando para crear aplicaciones más rápidas e inteligentes”.
Nadav Timor, doctorando en el Instituto Weizmann, añadió:
“Este trabajo elimina una barrera técnica importante para hacer que la IA generativa sea más rápida y económica”.
La siguiente imagen, compartida por Intel, ilustra de forma clara cómo esta técnica permite validar tokens en bloque y reducir significativamente el tiempo de inferencia:
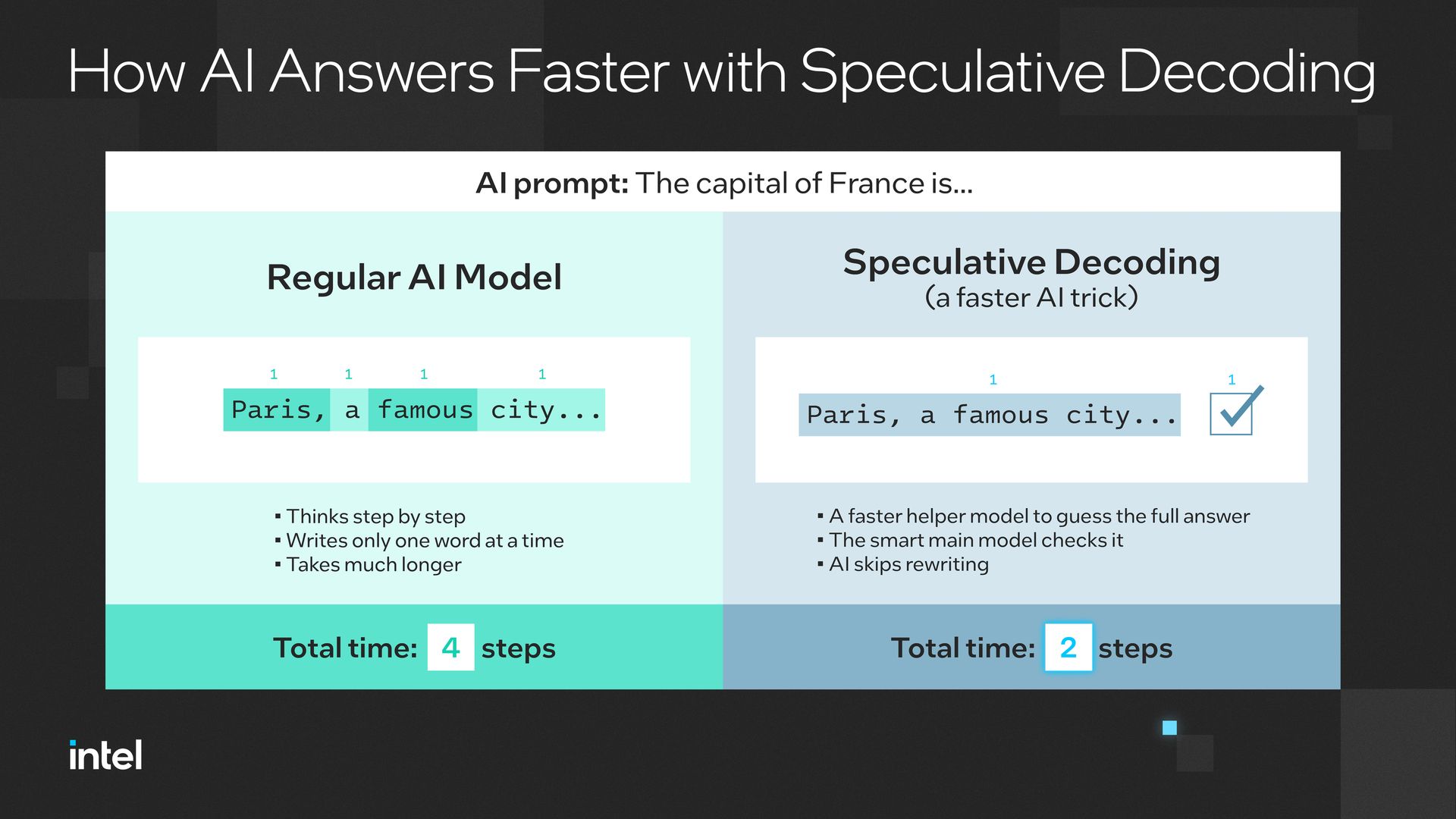
La siguiente tabla resume la diferencia entre el enfoque tradicional y el propuesto por Intel Labs.
