
DeepSeek presentó en vista previa técnica su nueva serie V4, compuesta por los modelos DeepSeek-V4-Pro y DeepSeek-V4-Flash. Ambos usan una arquitectura Mixture-of-Experts (MOE) y fueron diseñados para trabajar con ventanas de contexto de hasta 1 millón de tokens, un salto que no depende solo de escalar parámetros, sino también de cambios en atención, memoria y cuantización.
La serie se divide en dos modelos:
- Versión Pro apunta al mayor rendimiento, con 1,6 billones de parámetros totales y 49.000 millones activos por token.
- Versión Flash reduce el tamaño a 284.000 millones de parámetros totales y 13.000 millones activos para priorizar eficiencia.
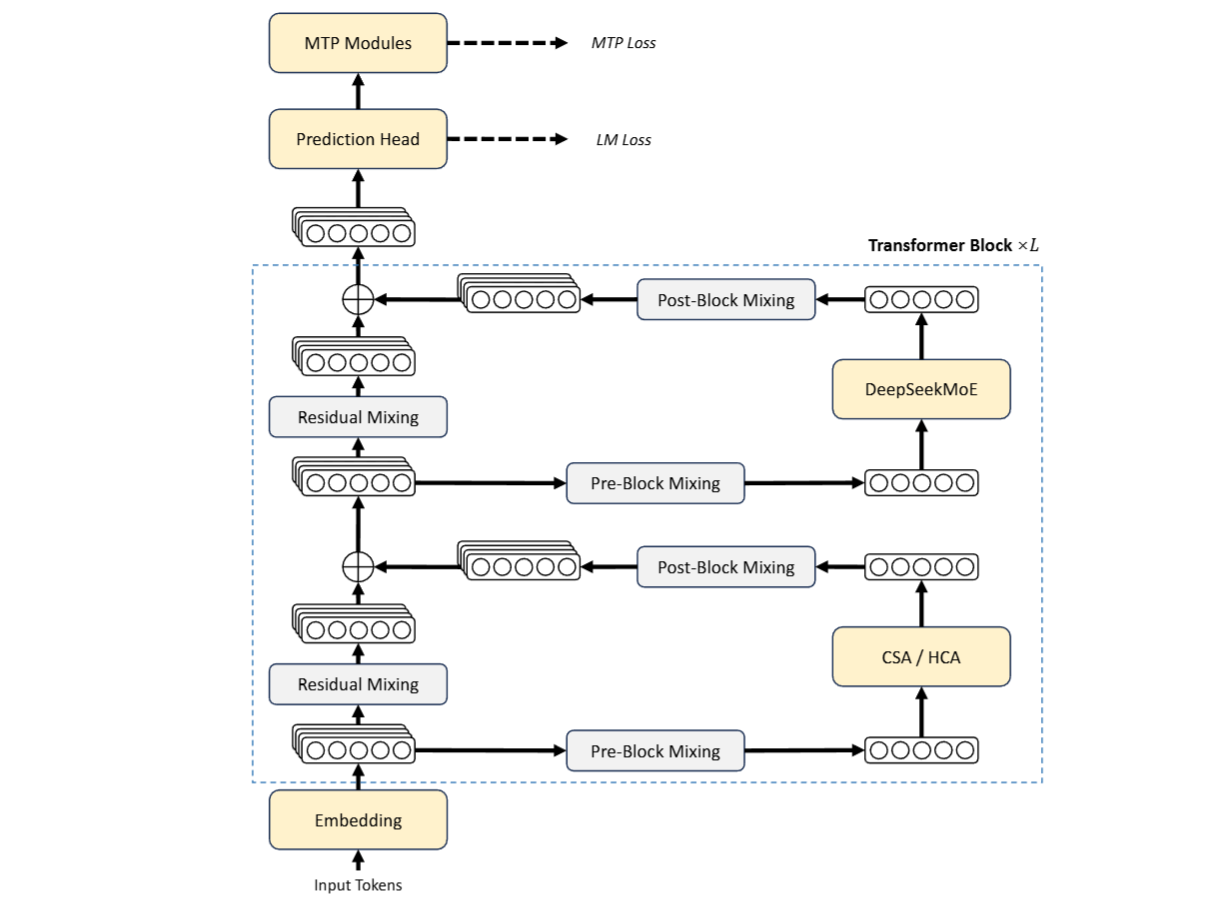
Dicho de otro modo, la arquitectura de DeepSeek-V4 funciona como un equipo de especialistas que revisa un documento enorme sin leerlo completo cada vez. Primero ordena el contenido, luego reduce las partes menos relevantes, conserva los fragmentos útiles y activa solo los módulos necesarios para construir una respuesta con menor uso de memoria y procesamiento.
¿Cómo DeepSeek-V4 procesa textos mucho más largos?
Para sostener contexto largo, DeepSeek-V4 combina Compressed Sparse Attention (atención dispersa comprimida) y Heavily Compressed Attention (atención fuertemente comprimida). El objetivo es reducir el costo de procesar secuencias extensas mediante compresión de la caché de claves y valores, seguida por selección dispersa de los bloques más relevantes.
A ese esquema se suma el uso de Manifold-Constrained Hyper-Connections (hiperconexiones restringidas por variedades), una técnica que reorganiza las conexiones residuales para estabilizar el entrenamiento y la propagación de señales. En conjunto, estas piezas forman la base de una arquitectura pensada para escalar longitud de contexto sin arrastrar el crecimiento cuadrático típico de la atención convencional.
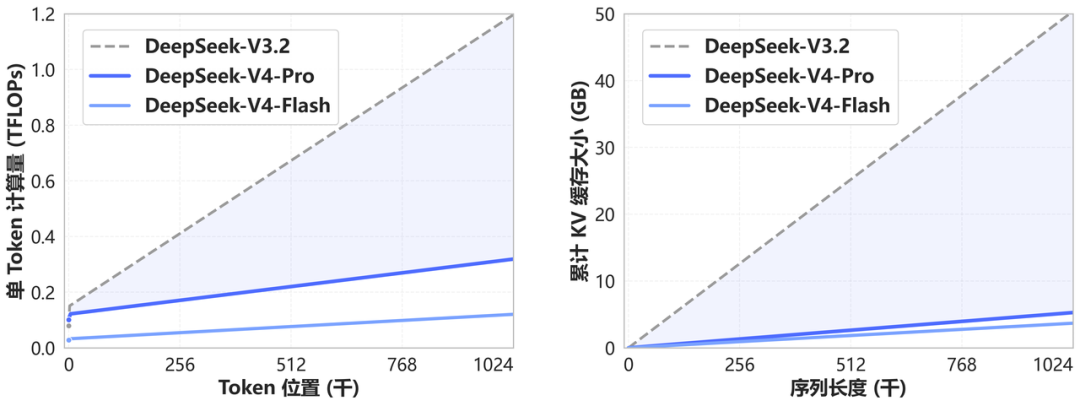
Los números que entrega el reporte de la firma muestran ese cambio con claridad:
- DeepSeek-V4-Pro usa 27% de los FLOPs por token de DeepSeek-V3.2 en contexto de 1 millón de tokens. y reduce la caché KV a 10% frente a DeepSeek-V3.2.
- DeepSeek-V4-Flash baja a 10% de los FLOPs por token y reduce la caché KV a 7% bajo la misma longitud de secuencia.
¿Qué muestran sus pruebas frente a otros modelos de IA?
En evaluación, DeepSeek-V4-Pro muestra mejoras en múltiples pruebas frente a DeepSeek-V3.2 Base, tanto en conocimiento general como en razonamiento, código y contexto largo. La tabla comparativa del documento le asigna, por ejemplo, 83,1 en AGIEval, 90,1 en MMLU, 73,5 en MMLU-Pro, 76,8 en HumanEval Pass@1 y 51,5 en LongBench-V2.
Además de la comparación interna con DeepSeek-V3.2 Base, el informe incluye una medición frente a modelos cerrados en tareas de conocimiento, razonamiento, programación y capacidades agénticas. En esa lectura, DeepSeek-V4-Pro-Max aparece como la variante usada para contrastar el rendimiento de la serie frente a Claude Opus 4.6 Max, GPT-5.4 xHigh y Gemini 3.1 Pro High.
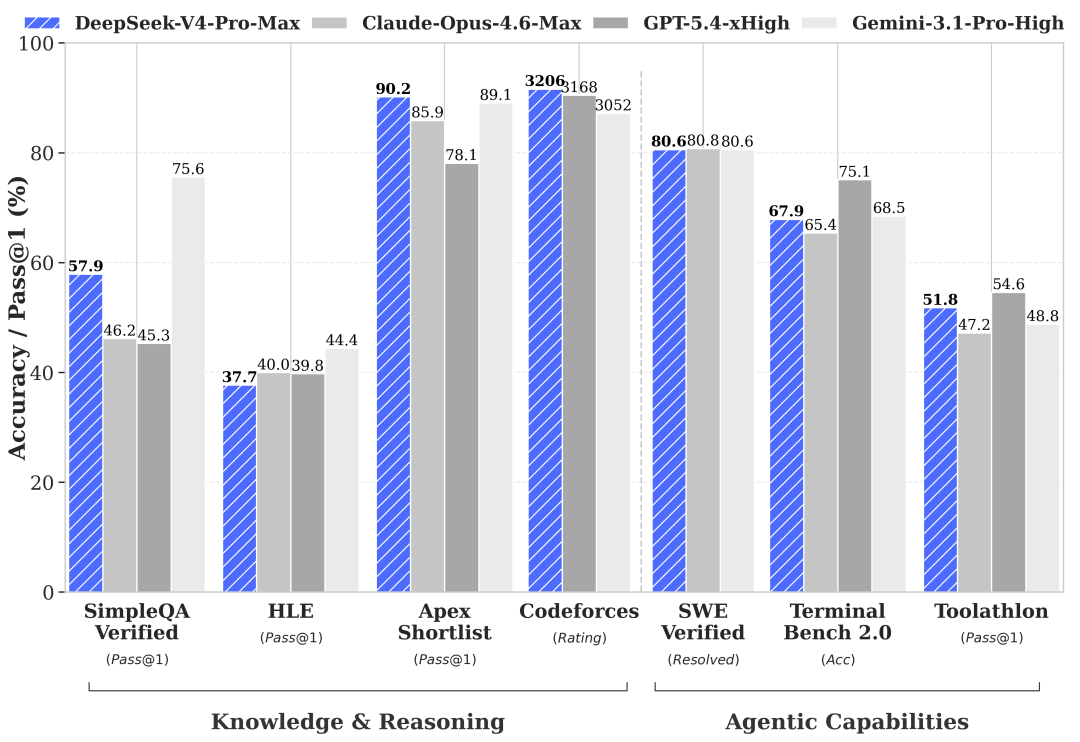
DeepSeek-V4-Flash también mejora sobre DeepSeek-V3.2 en varios escenarios, aunque con un perfil más orientado a eficiencia. En la misma tabla aparece con 82,6 en AGIEval, 88,7 en MMLU, 69,5 en HumanEval Pass@1 y 44,7 en LongBench-V2.
Otro punto importante del documento es la adopción de Quantization-Aware Training (entrenamiento consciente de cuantización) para llevar los pesos de los expertos a formato FP4.. La idea es reducir presión de memoria y tráfico de lectura sin romper la estabilidad del entrenamiento ni degradar de forma importante la recuperación de información.
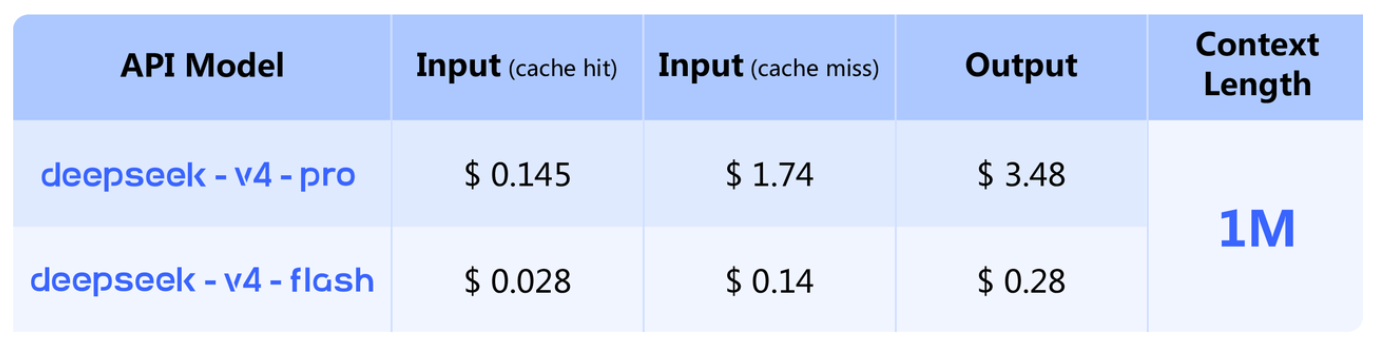
A nivel de despliegue, la ventana de 1 millón de tokens está habilitada por defecto en la API. La plataforma también permite alternar entre modos de respuesta más directos y ciclos de razonamiento más extensos, mientras prepara el retiro de los endpoints antiguos deepseek-chat y deepseek-reasoner.
Fuente: DeepSeek
