
SuperQ Quantum Computing Inc. presentó en el CES 2026 su aplicación ChatQLM, descrita comercialmente como una “app de consumo impulsada por cuántica”. Sin embargo, un análisis técnico de la patente provisional y arquitectura revela que no se trata de una IA generativa cuántica, sino de una plataforma de orquestación híbrida (Quantum Leveraged Model).

Dicho de una manera simple, ChatQLM no es una IA cuántica. Si descargas la aplicación presentada por SuperQ, no estás instalando un qubit en tu smartphone, ni estás ejecutando redes neuronales cuánticas nativas.
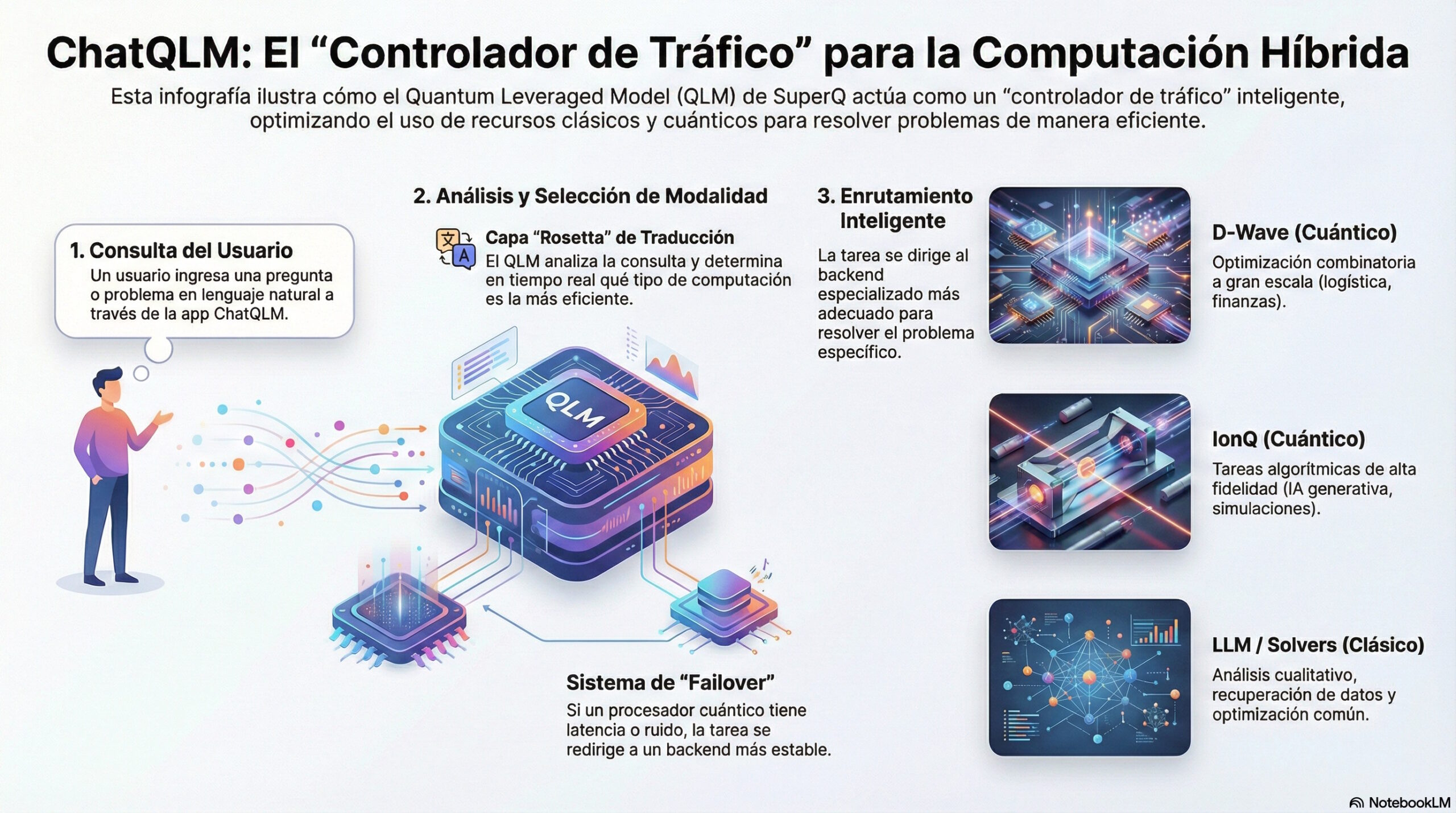
En el papel, la propuesta de la firma canadiense es una interfaz de cliente (frontend) que no ejecuta cómputo cuántico localmente. Su función real es actuar como un “controlador de tráfico” inteligente que clasifica las peticiones del usuario y las deriva al hardware más eficiente para cada tarea específica, sea clásico o cuántico.
El concepto: Un «router» de alto nivel
ChatQLM funciona como un jefe de obra o un contratista general. Tú (el cliente) le das una orden en lenguaje natural y la app (el contratista) analiza el pedido y decide a qué subcontratista llamar; no intenta hacerlo todo ella misma.
La patente provisional que presentó la firma detalla una tecnología llamada QLM (Quantum Leveraged Model). En palabras simples, esto es un sistema de clasificación de prompts que opera en hardware clásico. Su única función es discriminar el tipo de problema computacional que le planteas.
¿Qué es el modelo QLM y su flujo de trabajo?
El modelo QLM no es un nuevo procesador, sino una capa lógica de decisión alojada en la nube. La innovación real no está en que el teléfono haga cálculos complejos, sino en la capa de traducción (denominada en su patente como Vendor-Agnostic Rosetta Layer).
El flujo de trabajo técnico opera bajo una lógica de “Selección Dinámica de Modalidad”:
- Input en lenguaje natural: El usuario introduce un prompt en la app móvil.
- Capa Rosetta (Vendor-Agnostic Layer): El sistema traduce la petición de lenguaje natural a código máquina específico para diferentes arquitecturas.
- Enrutamiento inteligente: El algoritmo evalúa la naturaleza del problema y asigna el backend correspondiente:
- D-Wave (Quantum Annealing): Se activa exclusivamente para problemas de optimización combinatoria de alta escala, como logística, cadenas de suministro o balanceo de portafolios financieros.
- IonQ (Gate-Based Systems): Se utiliza para tareas algorítmicas de alta fidelidad, como simulaciones moleculares o análisis complejos de árboles de decisión que requieren sistemas de iones atrapados.
- LLM Clásico / GPU NVIDIA: Para análisis cualitativo, redacción de texto, recuperación de datos y parsing de contenido, el sistema utiliza modelos de lenguaje tradicionales ejecutados en GPUs.
- Solvers Clásicos: Para problemas de optimización matemática lineal que no justifican el uso de QPU (Unidades de Procesamiento Cuántico).
Desglose técnico: 1 AI y 4 motores de cálculo
El ecosistema QLM (Quantum Leveraged Model) se compone de una sola interfaz semántica apoyada por cuatro tipos de backends de fuerza bruta (motores). No todo es IA; gran parte es física y matemática pura.
Failover y abstracción de hardware
Uno de los puntos críticos mencionados en la documentación técnica es el sistema de “Consumer-Ready Failover”. Dado que el hardware cuántico actual (NISQ) es susceptible al ruido y la decoherencia, el orquestador realiza benchmarking en tiempo real.
Si detecta latencia alta o inestabilidad en el procesador cuántico (D-Wave o IonQ), el sistema redirige automáticamente la tarea a un backend clásico sin intervención del usuario.
En resumen, ChatQLM es una solución de software que omite la complejidad de programar para diferentes arquitecturas cuánticas, permitiendo interactuar con máquinas de D-Wave e IonQ a través de lenguaje natural, pero manteniendo el procesamiento pesado fuera del dispositivo del usuario.
Fuentes: 1 / 2 / 3
