
Anthropic oficializó su aterrizaje en salud con su modelo más potente, Opus 4.5. Junto a gigantes como Pfizer, la firma busca incorporar su tecnología en la rutina de clínicas y centros de investigación, apuntando a esos procesos sensibles donde se busca reducir al mínimo los errores.
La propuesta técnica de Anthropic apunta a resolver el caos de la información médica dispersa entre distintos sistemas que hoy son incompatibles. La nueva plataforma promete acelerar el descubrimiento de fármacos y diagnósticos, manteniendo el cumplimiento de normas estrictas de privacidad como el estándar HIPAA.
La fragmentación de la información en los historiales clínicos sigue siendo un problema latente. En la entrevista con María Paulina Salinas se profundizó en la falta de interoperabilidad en salud, una barrera estructural que impide transformar los registros disponibles en decisiones clínicas efectivas.
Aceleración de ensayos y automatización regulatoria
La integración de estos modelos en entornos farmacéuticos permite automatizar la generación de documentos críticos. Un caso destacado es el de Novo Nordisk, que mediante su solución NovoScribe ha logrado reducir la redacción de informes de estudios clínicos de 12 semanas a 10 minutos.
Por su parte, Pfizer reportó una reducción en sus ciclos de prototipado de tres meses a seis semanas. Esta optimización liberó 16.000 horas anuales de investigación que anteriormente se destinaban a la búsqueda manual de información.
La ejecutiva Louise Lind Skov destacó el impacto de esta tecnología en la cadena de desarrollo farmacéutico:
“Hemos sido constantemente uno de los primeros en adoptar la automatización de documentos y contenido en el desarrollo farmacéutico. Nuestro trabajo con Anthropic y Claude ha establecido un nuevo estándar: no solo estamos automatizando tareas, estamos transformando cómo los medicamentos llegan desde el descubrimiento hasta los pacientes que los necesitan”.
Louise Lind Skov, directora de digitalización de Contenidos, Novo Nordisk
Dominio en benchmarks técnicos y razonamiento médico
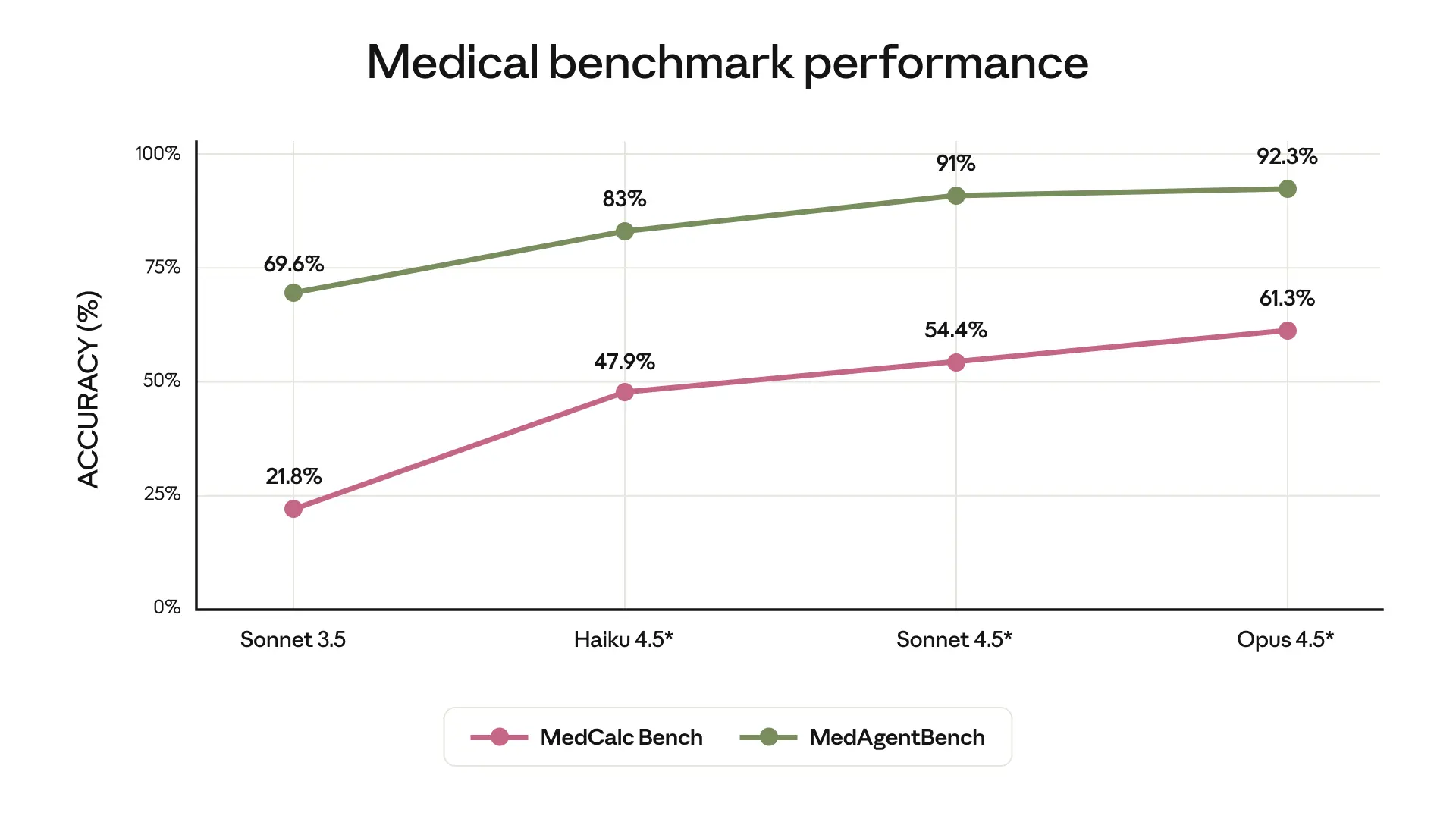
El lanzamiento del modelo Opus 4.5 marca un nuevo estándar en la evaluación de agentes de IA en medicina. Según los datos presentados, este modelo supera significativamente a sus predecesores y competidores en tareas de cálculo médico y gestión de agentes clínicos.
El rendimiento técnico se desglosa en las siguientes métricas clave, ilustradas más abajo:
- MedAgentBench (Stanford): Opus 4.5 alcanzó un 92.3% de precisión en la finalización de tareas de agentes médicos.
- MedCalc Bench: En precisión de cálculos médicos con ejecución de código Python, el modelo logró un 61.3%, superando al Sonnet 4.5 (54.4%).
- Evolución: Se observa un salto cualitativo desde el 21.8% del modelo Sonnet 3.5 en tareas de cálculo hasta los niveles actuales.
Avances en biología computacional y espacial
Además de la medicina clínica, la capacidad de los modelos para interpretar datos biológicos complejos ha mostrado un crecimiento sostenido. Las evaluaciones internas indican mejoras sustanciales en la interpretación de figuras científicas y comprensión de proteínas entre agosto y noviembre de 2025, como se observa en la gráfica.
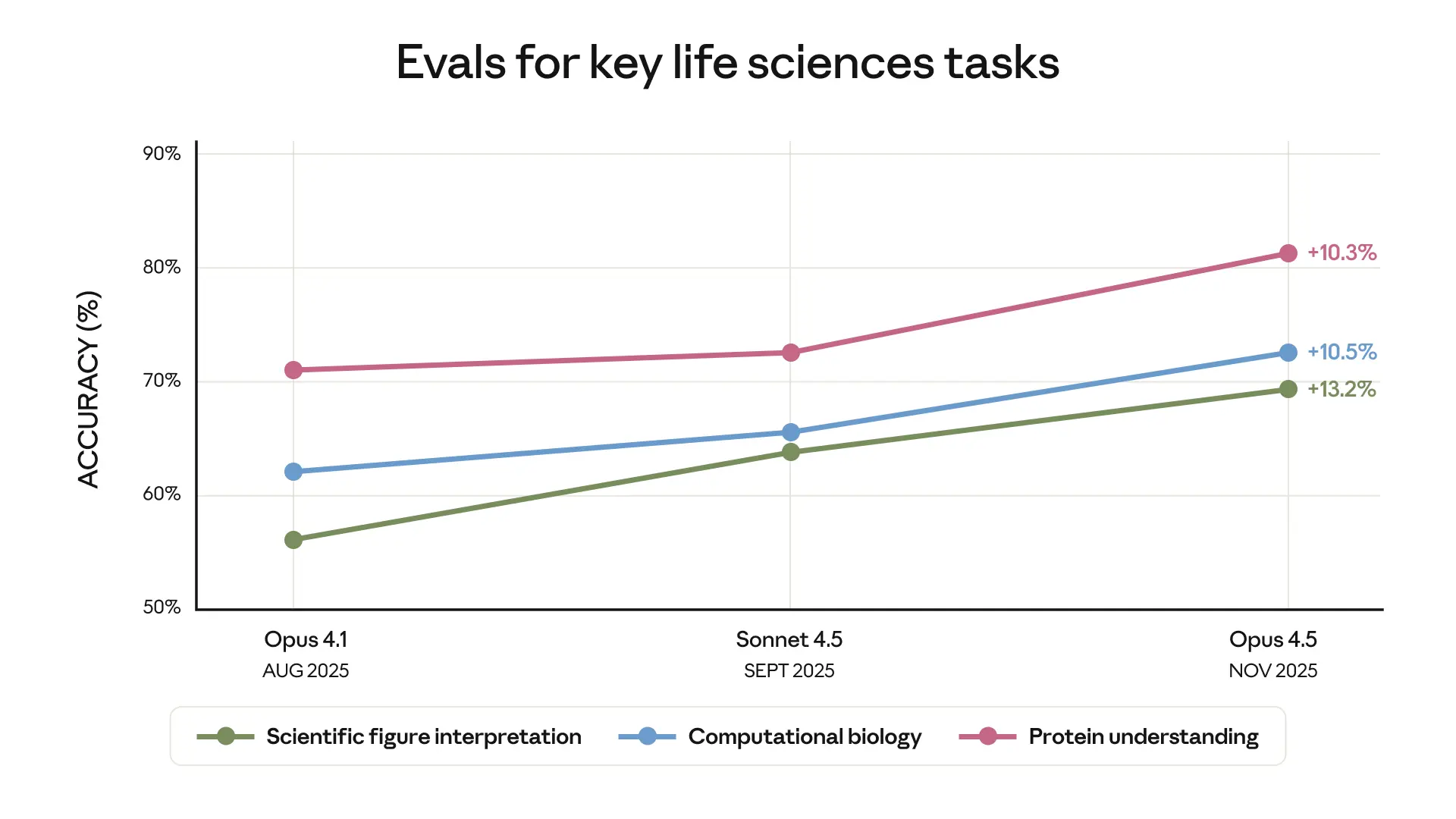
Los datos de evaluación para tareas de ciencias de la vida muestran:
- Interpretación de figuras científicas: Aumento del 13.2% en precisión entre Opus 4.1 y Opus 4.5.
- Biología computacional: Mejora del 10.5% en el mismo periodo.
- Comprensión de proteínas: Incremento del 10.3%, alcanzando niveles superiores al 80% de precisión.
En pruebas independientes realizadas por terceros, el liderazgo técnico se mantiene frente a otros modelos del mercado. LatchBio condujo el benchmark “SpatialBench”, diseñado para medir la capacidad de análisis en biología espacial, un campo que estudia la disposición física de las células en los tejidos.
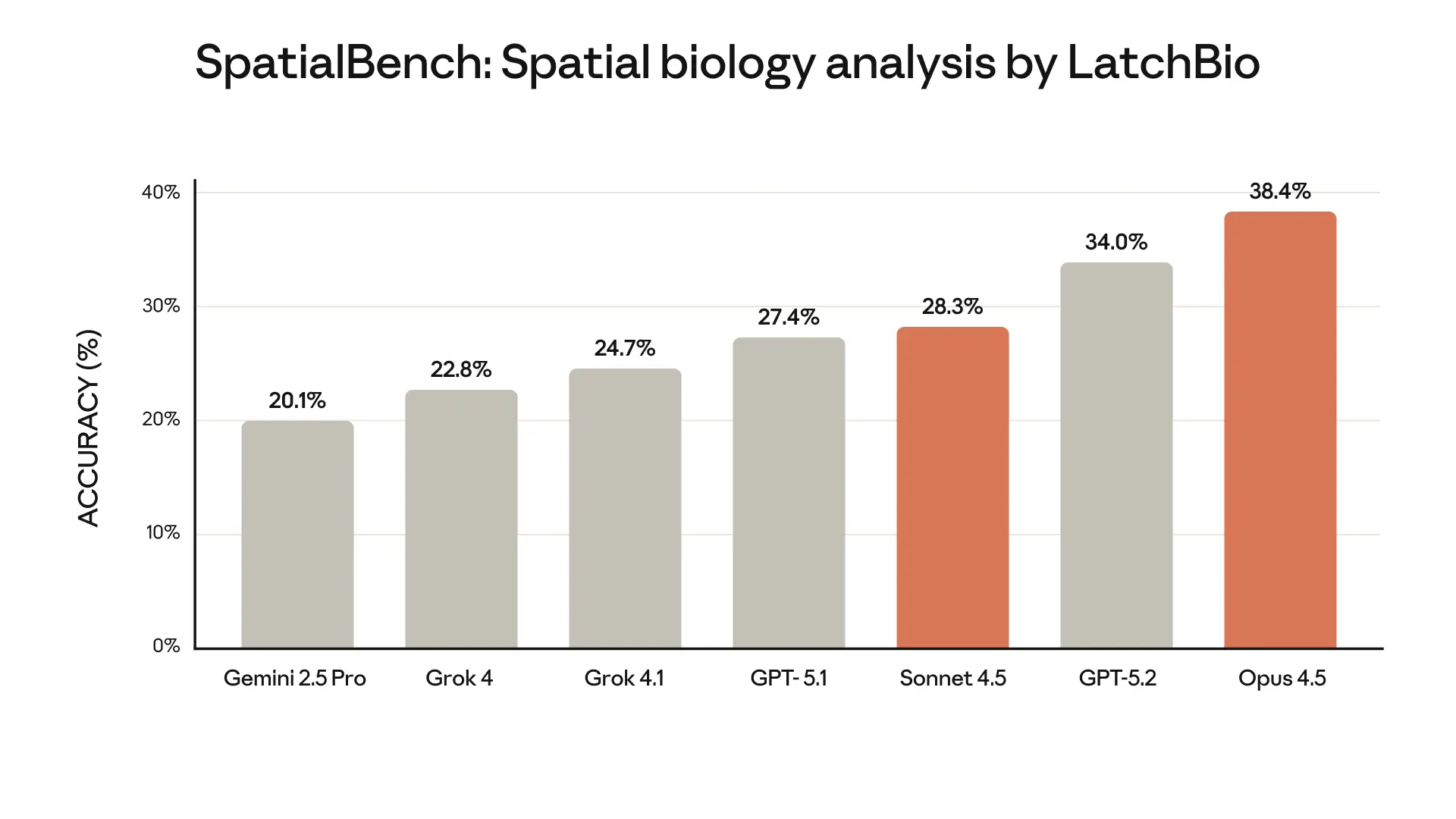
Los resultados de este análisis comparativo, presentados de barras:
- Opus 4.5: Lidera la tabla con un 38.4% de precisión.
- GPT-5.2: Se ubica en segundo lugar con un 34.0%.
- Sonnet 4.5: Mantiene un rendimiento competitivo del 28.3%, superando a modelos anteriores como GPT-5.1.
Impacto en la eficiencia operativa y administrativa
Más allá del descubrimiento científico, la implementación de Opus 4.5 aborda la carga administrativa que satura los sistemas de salud. Análisis técnicos de firmas especializadas como Intuition Labs detallan aplicaciones prácticas en flujos de trabajo hospitalarios y farmacéuticos.
La siguiente tabla, desarrollada por Intuition Labs, resume cómo Opus 4.5 y otros modelos de IA orientados a codificación pueden incorporarse en flujos de trabajo sanitarios y farmacéuticos. Cada fila explica una tarea concreta, el valor que aporta la IA y los beneficios que se obtienen. Cuando es posible, se incluyen referencias a estudios o casos reales que respaldan su uso.
Infraestructura de seguridad y cumplimiento normativo
Meter datos de pacientes en una IA suele encender las alarmas de privacidad de cualquier equipo médico. Para evitar fugas, Anthropic montó su operación sobre una arquitectura que aísla el procesamiento de la información sensible, garantizando que los datos no se usen para reentrenar modelos públicos.
El stack técnico de seguridad se compone de los siguientes protocolos:
- Infraestructura base: Despliegue a través de Amazon Bedrock.
- Cumplimiento normativo: Certificaciones habilitadas para HIPAA y SOC 2.
- Control de comportamiento: Metodología de «IA Constitucional» (Constitutional AI) para forzar reglas éticas.
- Gestión de datos: Entorno aislado para información de salud protegida (PHI).
