

Anthropic presentó Claude Sonnet 5 como su IA más orientado a tareas de agénticas, con foco en planificación, uso de navegadores y terminales, y ejecución autónoma. La firma lo presenta como una mejora frente a Sonnet 4.6 y como una alternativa cercana a Opus 4.8 en varias evaluaciones, pero con precios menores en la API.
Sonnet 5 sube frente a 4.6 y queda cerca de Opus 4.8
En la tabla de evaluaciones, Sonnet 5 supera a Sonnet 4.6 en codificación, razonamiento multidisciplinario, uso de computador y trabajo de conocimiento. La comparación también muestra que se acerca a Opus 4.8 en Terminal-Bench 2.1, OSWorld-Verified y Humanity’s Last Exam con herramientas, aunque sigue por debajo en SWE-bench Pro y en Humanity’s Last Exam sin herramientas.
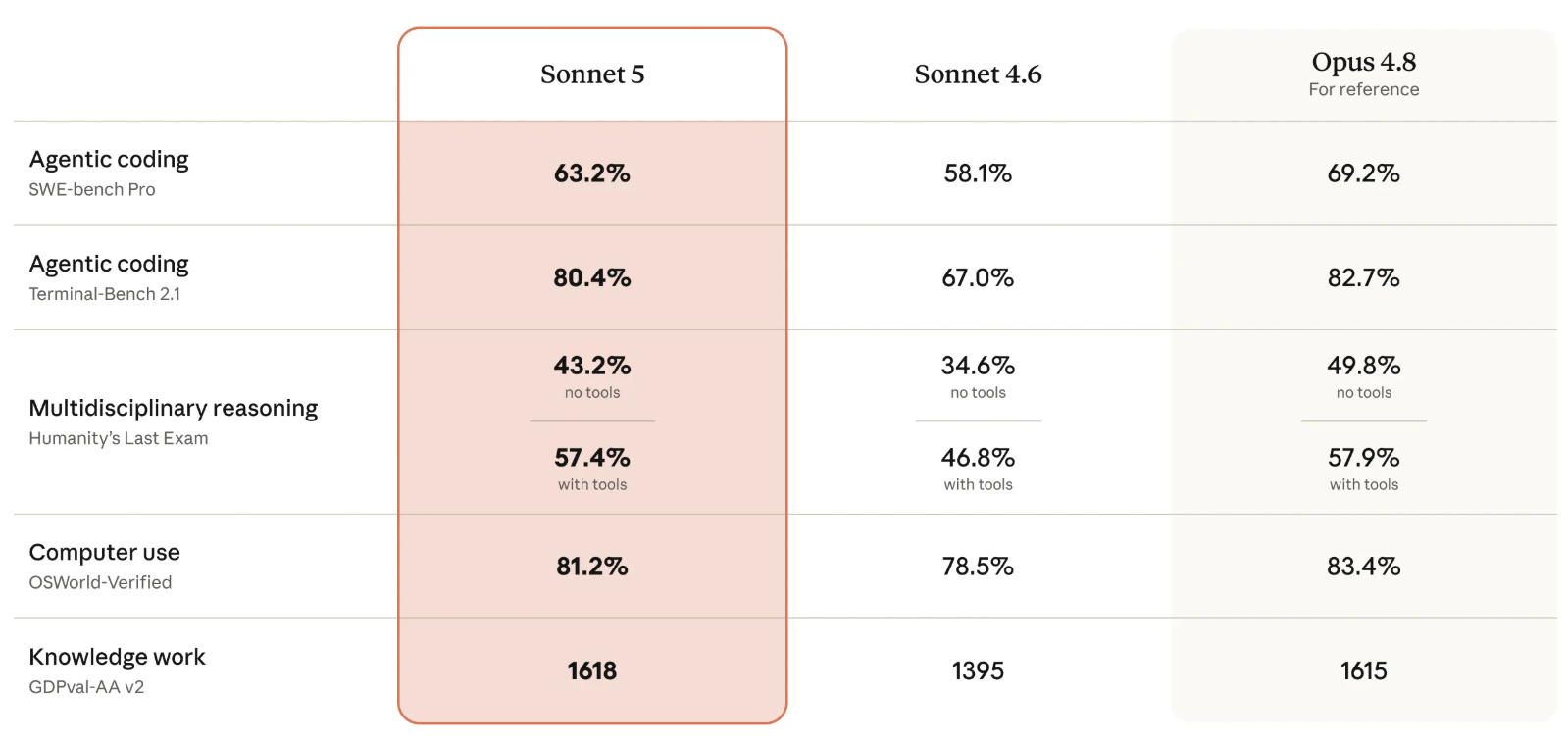
En GDPval-AA v2, Sonnet 5 aparece con 1618 puntos, levemente por encima de los 1615 de Opus 4.8. Ese resultado corresponde a una evaluación específica de trabajo de conocimiento y no reemplaza la comparación general, donde Anthropic sigue usando Opus 4.8 como referencia de mayor capacidad.
Las curvas de costo muestran el efecto del nivel de esfuerzo
Búsqueda autónoma en internet: rendimiento vs. costo
Anthropic comparó Sonnet 5, Sonnet 4.6 y Opus 4.8 con distintos niveles de esfuerzo en BrowseComp y OSWorld-Verified. Las curvas usan el precio estándar futuro de Sonnet 5, de 3 dólares por millón de tokens de entrada y 15 dólares por millón de tokens de salida. (No el precio inicial que rige hasta el 31 de agosto).
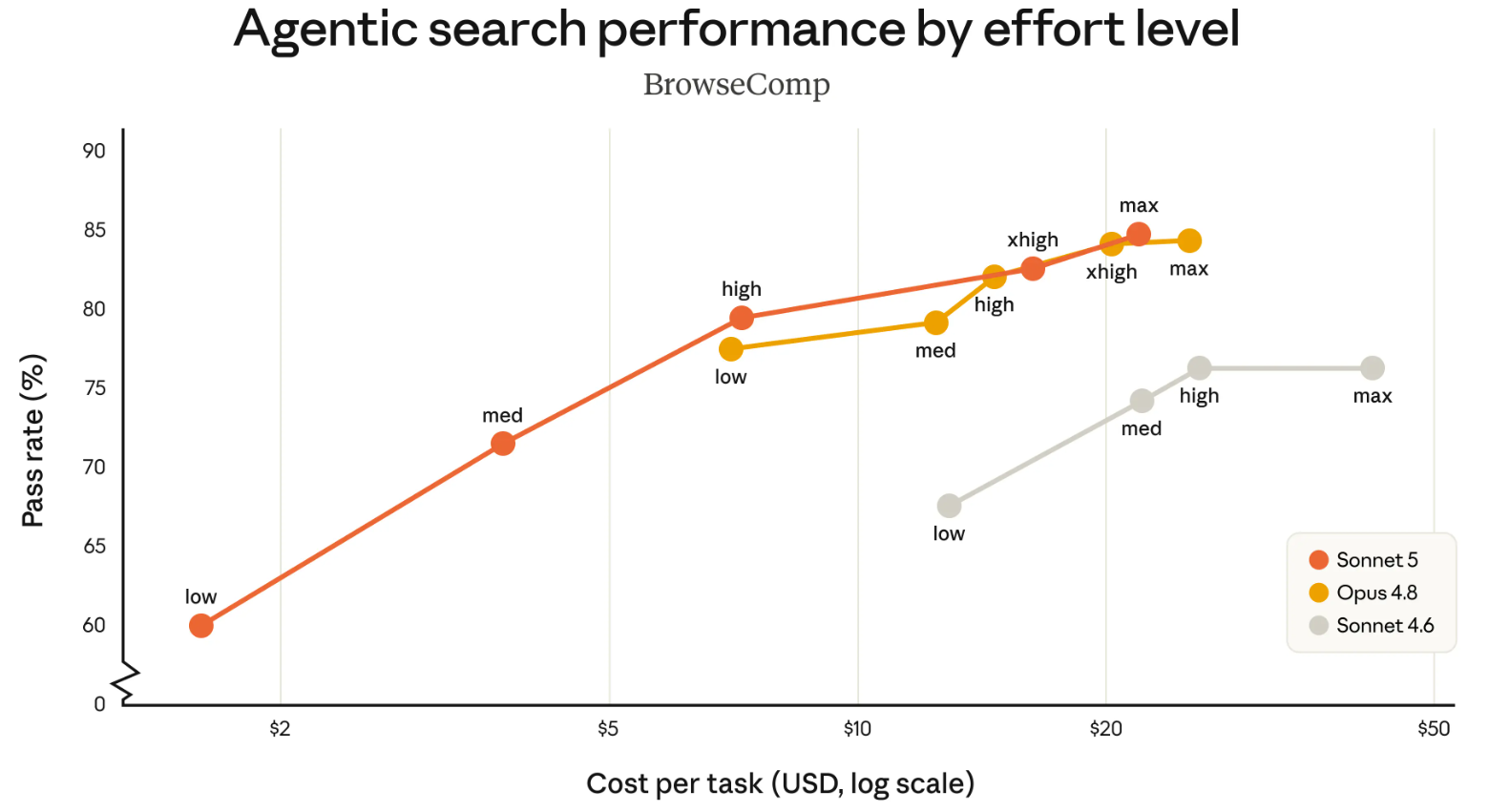
El gráfico anterior mide qué tan bien cada modelo de IA busca información en internet por su cuenta, resolviendo tareas de investigación de varios pasos sin guía humana. Compara rendimiento contra costo para ver qué modelo entrega más aciertos por dólar gastado.
- Eje vertical (Pass rate %): porcentaje de tareas que el modelo completa correctamente. Más arriba = mejor.
- Eje horizontal (Cost per task): cuánto cuesta cada tarea en dólares, en escala logarítmica.
- Puntos «low» a «max»: nivel de esfuerzo o razonamiento que se le permite al modelo. Más esfuerzo suele dar más aciertos, pero también más costo.
- Lectura rápida: mientras más arriba y a la derecha está un punto, mejor lo hace el modelo, aunque pagando más.
Uso de computador por la IA: rendimiento vs. costo
En BrowseComp, Sonnet 5 aparece con una curva de costo y rendimiento más amplia que Sonnet 4.6 y alcanza zonas cercanas a Opus 4.8 en niveles altos. En OSWorld-Verified, Opus 4.8 mantiene el resultado más alto, mientras Sonnet 5 queda por encima de Sonnet 4.6 en los tramos mostrados.
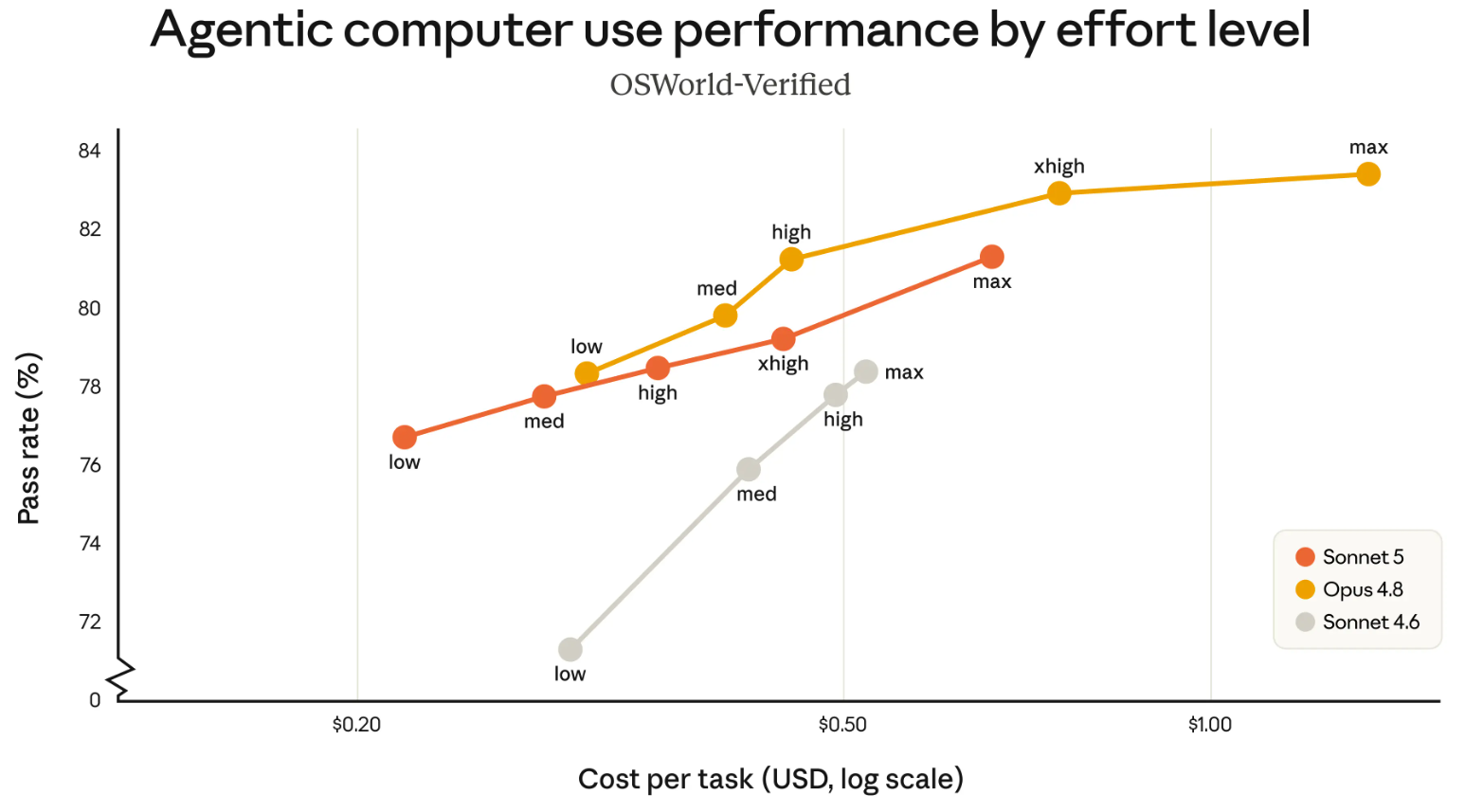
En esta situación la IA tiene que operar un computador por sí sola: abrir programas, mover el mouse, hacer clic, escribir y completar tareas reales como lo haría una persona frente a la pantalla.
- Eje vertical (Pass rate %): porcentaje de tareas de computador que el modelo logra hacer bien.
- Eje horizontal (Cost per task): costo por tarea en dólares, también en escala logarítmica.
- Puntos «low» a «max»: mismos niveles de esfuerzo; más razonamiento mejora el rendimiento a cambio de mayor costo.
- Se ve el equilibrio entre qué tan capaz es cada modelo y cuánto cuesta hacerlo funcionar.
Seguridad: menos conducta desalineada que Sonnet 4.6, pero más que Opus 4.8
Las evaluaciones previas al despliegue reportan mejoras frente a Sonnet 4.6 en rechazo de solicitudes maliciosas, resistencia a inyecciones de prompt, alucinaciones y complacencia indebida. En la auditoría conductual automatizada, Sonnet 5 obtiene 2.53 puntos, por debajo de Sonnet 4.6, pero por encima de Opus 4.8 y Mythos Preview.
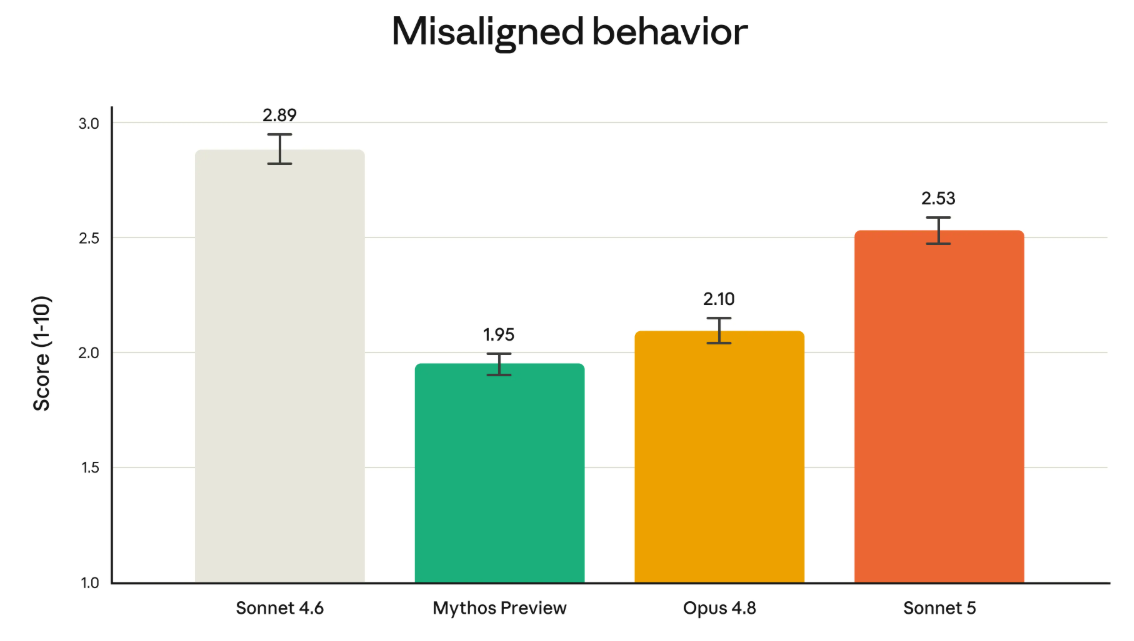
Este gráfico mide qué tan seguido cada modelo de IA se comporta de forma «desalineada», es decir, cuando hace cosas que no debería: obedecer solicitudes maliciosas, dejarse engañar, inventar información o adular al usuario en vez de decirle la verdad.
- Eje vertical (Score 1-10): nivel de conducta desalineada detectado en la auditoría. Más bajo = más seguro.
- Cada barra: un modelo distinto. Las líneas negras sobre las barras marcan el margen de error de la medición. A diferencia de los gráficos anteriores, acá menos es mejor: una barra más baja significa que el modelo se porta mal con menos frecuencia.
- Mythos Preview es el más seguro (1.95), seguido de Opus 4.8 (2.10), luego Sonnet 5 (2.53) y por último Sonnet 4.6 (2.89), que es el que más falla.
- Sonnet 5 mejora respecto de su versión anterior (Sonnet 4.6), pero todavía no alcanza el nivel de seguridad de Opus 4.8.
En ciberseguridad, Anthropic mantiene resguardos por defecto
La firma indica que Sonnet 5 no fue entrenado deliberadamente para tareas de ciberseguridad, aunque puede ejecutar tareas rutinarias no dañinas. En la evaluación de desarrollo de exploits sobre Firefox 147, ambos modelos Sonnet marcaron 0,0% de exploits funcionales, mientras Sonnet 5 obtuvo 13,2% de éxito parcial frente al 8,8% de Sonnet 4.6.
El siguiente gráfico pone a prueba algo más delicado: ¿qué tan capaz es cada modelo de IA de crear un exploit, o sea, un programa que aprovecha una falla de seguridad para atacar un sistema? (en este caso, vulnerabilidades del navegador Firefox que ya fueron corregidas).
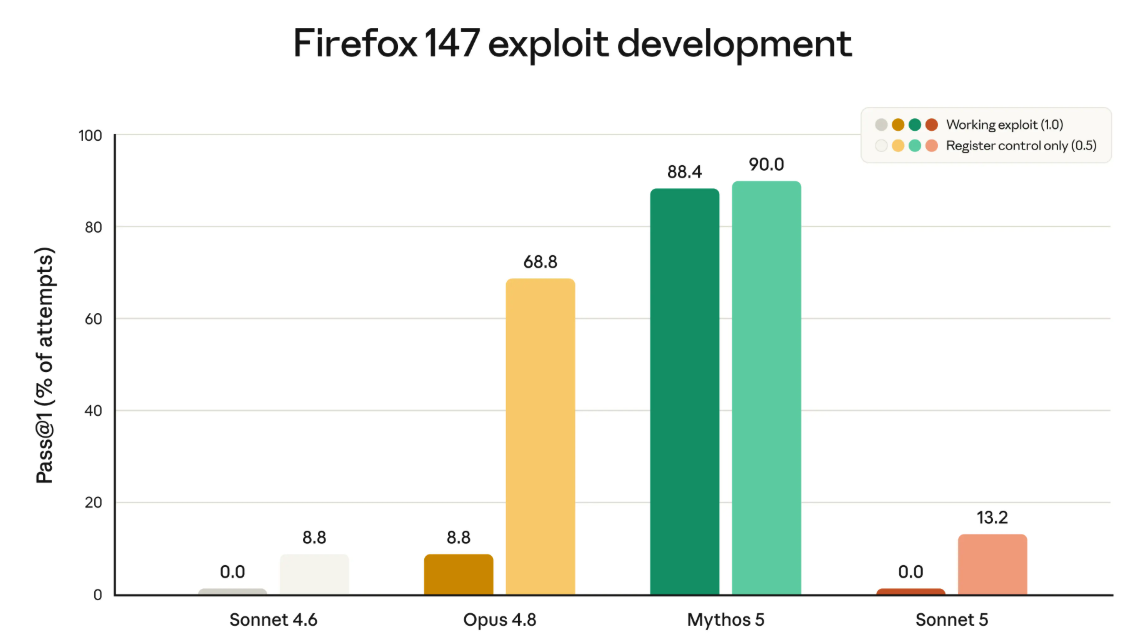
La data es una medición de seguridad al revés: acá interesa saber qué tan lejos puede llegar cada modelo en algo peligroso, para asegurarse de que los más nuevos no se vuelvan una herramienta de ataque. Hay dos niveles de «logro»: un ataque completamente funcional, o solo un avance parcial